philipperemy/stanford-openie-python
A Python life preserver for Stanford's Java NLP ship
This wrapper spares you from directly wrestling with Stanford CoreNLP's Java guts to extract relation triples from plain text.
Not currently ranked — collecting fresh signals.
star history
What it does
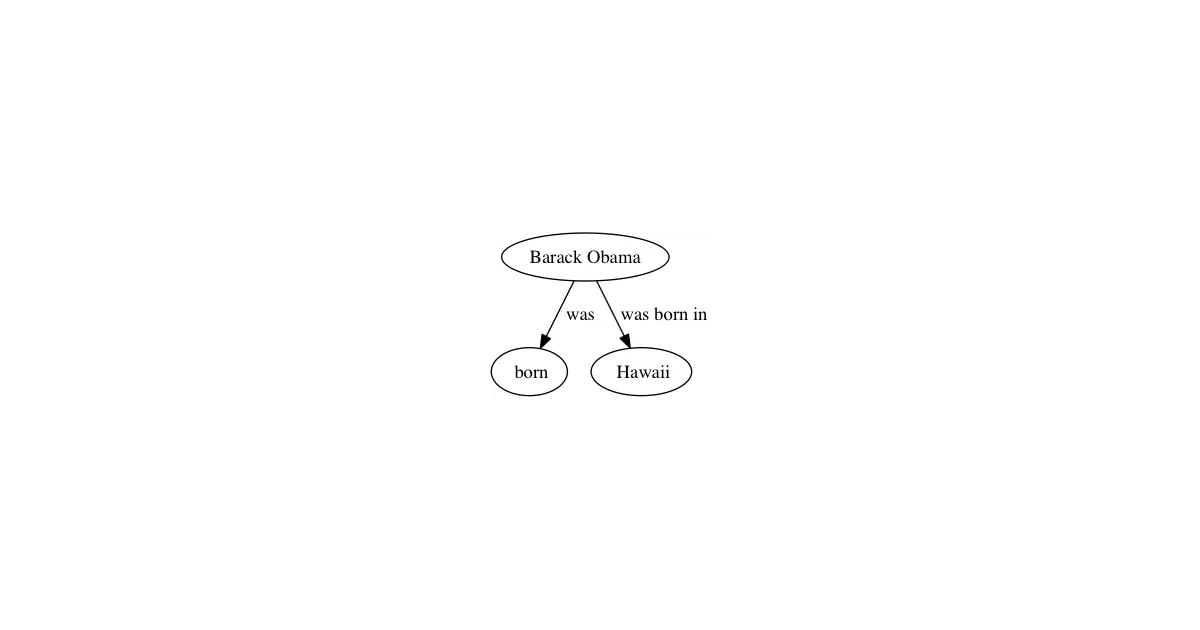
Stanford’s OpenIE system extracts structured relation triples—subject, relation, object—from unstructured text without predefined schemas. “Barack Obama was born in Hawaii” becomes (Barack Obama; was born in; Hawaii). This project wraps the Java-based CoreNLP library so you can call it from Python with context managers and simple methods.
The interesting bit
The wrapper handles the JVM orchestration and CoreNLP plumbing, but also throws in a GraphViz DOT generator so you can visualize your extracted triples as actual graphs. It’s a small convenience that saves you from writing the “call Java from Python, parse the output, munge into dicts” boilerplate yourself.
Key highlights
- Supports CoreNLP 4.5.3 (as of March 2023)
- Configurable confidence threshold via
openie.affinity_probability_cap - Returns clean Python dicts with
subject,relation,objectkeys - Optional graph visualization via GraphViz
- English-only; CoreNLP’s OpenIE doesn’t support other languages
Caveats
- Requires Java JRE installed separately; the wrapper won’t manage that for you
- GraphViz is another external dependency if you want the visualization feature
- The README’s example output shows some noisy extractions (
'was'as a relation for “was born”), which suggests the usual open IE precision trade-offs
Verdict
Worth a look if you need quick relation extraction from English text and would rather not maintain your own CoreNLP Java bridge. Skip it if you need multilingual support, or if you’re already deep in spaCy/NLTK land and don’t want the JVM baggage.
Frequently asked
- What is philipperemy/stanford-openie-python?
- This wrapper spares you from directly wrestling with Stanford CoreNLP's Java guts to extract relation triples from plain text.
- Is stanford-openie-python open source?
- Yes — philipperemy/stanford-openie-python is open source, released under the ISC license.
- What language is stanford-openie-python written in?
- philipperemy/stanford-openie-python is primarily written in Python.
- How popular is stanford-openie-python?
- philipperemy/stanford-openie-python has 682 stars on GitHub.
- Where can I find stanford-openie-python?
- philipperemy/stanford-openie-python is on GitHub at https://github.com/philipperemy/stanford-openie-python.