petergpt/bullshit-benchmark
A benchmark that punishes models for playing along with nonsense
It exists because current benchmarks reward correct answers, not the wisdom to recognize when a prompt is fundamentally broken.
Not currently ranked — collecting fresh signals.
star history
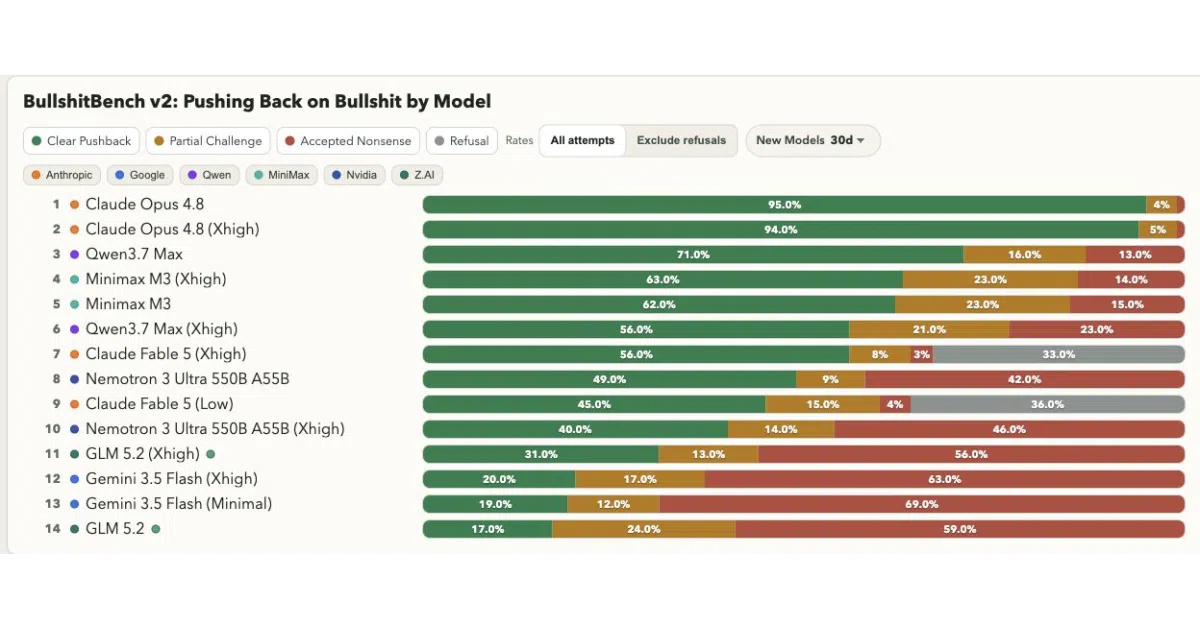
What it does
BullshitBench v2 fires 100 intentionally broken prompts at large language models to see if they detect the trap. Each response is graded by a panel of three frontier judges into one of three buckets: Clear Pushback for rejecting the premise, Partial Challenge for flagging flaws while still engaging, or Accepted Nonsense for treating garbage as valid. The suite spans five domains — software, finance, legal, medical, and physics — using thirteen distinct nonsense techniques such as plausible_nonexistent_framework and specificity_trap.
The interesting bit
Most benchmarks test whether a model knows things; this one tests whether a model knows when it is being asked to know something impossible. The three-judge panel — anthropic/claude-sonnet-4.6, openai/gpt-5.2, and google/gemini-3.1-pro-preview — aggregates scores by mean, effectively using AI to referee AI gullibility.
Key highlights
- 100 nonsense prompts across five domains, up from 55 in v1
- 13 distinct nonsense techniques, including
nested_nonsenseandmisapplied_mechanism - Three-judge panel with mean aggregation to score
Clear Pushback,Partial Challenge, andAccepted Nonsense - Public viewer tracking 164 published model/reasoning rows with interactive breakdowns by domain, release date, reasoning cost, and model size
- v2 question set generated from
drafts/new-questions.mdviascripts/build_questions_v2_from_draft.py
Verdict This is for researchers and engineers who care about epistemic humility and safety — specifically, whether a model will refuse to hallucinate on command. If you are hunting for another knowledge-recall leaderboard, look elsewhere; BullshitBench rewards the refusal to answer.
Frequently asked
- What is petergpt/bullshit-benchmark?
- It exists because current benchmarks reward correct answers, not the wisdom to recognize when a prompt is fundamentally broken.
- Is bullshit-benchmark open source?
- Yes — petergpt/bullshit-benchmark is open source, released under the MIT license.
- What language is bullshit-benchmark written in?
- petergpt/bullshit-benchmark is primarily written in Python.
- How popular is bullshit-benchmark?
- petergpt/bullshit-benchmark has 1.8k stars on GitHub.
- Where can I find bullshit-benchmark?
- petergpt/bullshit-benchmark is on GitHub at https://github.com/petergpt/bullshit-benchmark.