paralleldrive/riteway
Unit tests that grade your AI agent's homework
Riteway is a testing framework that now doubles as a prompt-evaluation harness for Claude, Cursor, and other coding agents.
Not currently ranked — collecting fresh signals.
star history
What it does
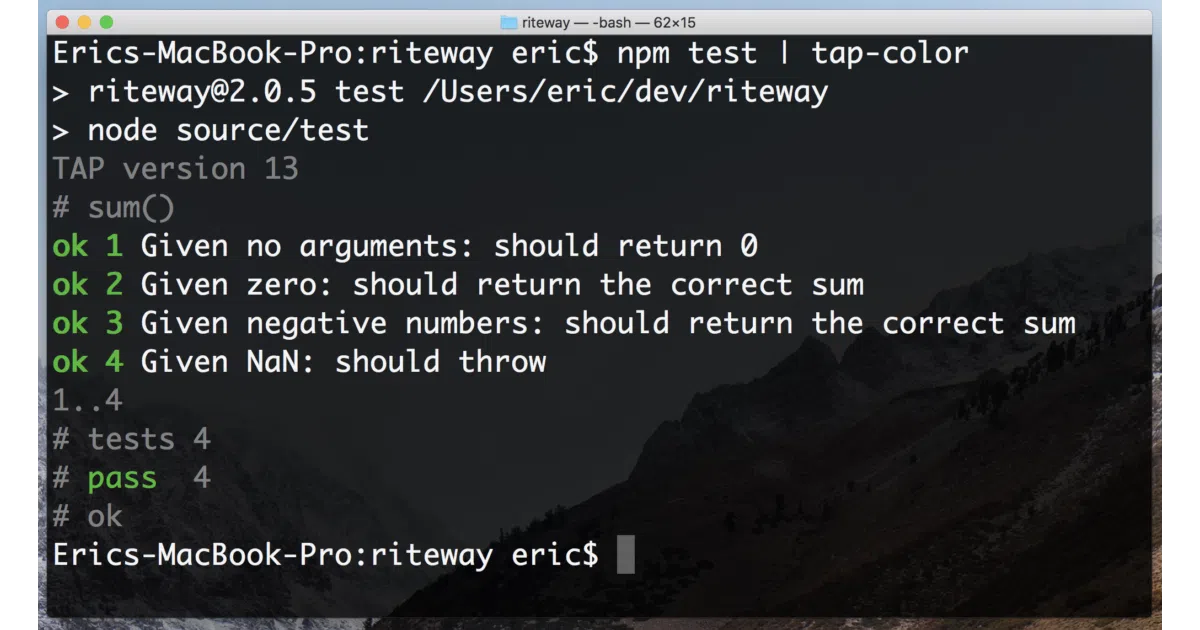
Riteway is a JavaScript unit-testing library built around a rigid assertion style: every test must spell out given, should, actual, and expected. The API is intentionally minimal—there are no matchers, no chains, no .toBeTruthy() rabbit holes. It also ships with a riteway ai CLI that runs prompt evaluations against LLM agents and scores them across multiple passes.
The interesting bit
The riteway ai command treats AI agents like unreliable test subjects. You write .sudo files in SudoLang syntax, the agent responds to a prompt, and a judge agent scores each assertion. It defaults to 4 runs with a 75 % pass-rate threshold—statistical rigor for a notoriously stochastic process. The output is TAP, so you can pipe it into existing CI dashboards.
Key highlights
- Forces the “5 questions” framework on every test: unit, behavior, actual, expected, reproduction.
riteway aisupports Claude, Cursor, and OpenCode via OAuth—no API keys in env vars.- Custom agents via
riteway.agent-config.json; theinitcommand bootstraps the file. --save-responseswrites per-run judge details for debugging flaky agent behavior.- React component helper included, though the docs nudge you toward pure components and away from mocking.
Caveats
- Requires Node 16+ and native ESM; JSX testing needs a separate transpiler setup.
- The README truncates mid-sentence in the React factory-function section, so some details are literally cut off.
- AI evals rely on external agent CLIs being installed and authenticated separately.
Verdict Worth a look if you’re running AI-assisted development and want to regression-test your prompts like code. Skip it if you’re happy with Vitest alone and don’t need to benchmark Claude’s consistency.
Frequently asked
- What is paralleldrive/riteway?
- Riteway is a testing framework that now doubles as a prompt-evaluation harness for Claude, Cursor, and other coding agents.
- Is riteway open source?
- Yes — paralleldrive/riteway is open source, released under the MIT license.
- What language is riteway written in?
- paralleldrive/riteway is primarily written in JavaScript.
- How popular is riteway?
- paralleldrive/riteway has 1.2k stars on GitHub.
- Where can I find riteway?
- paralleldrive/riteway is on GitHub at https://github.com/paralleldrive/riteway.