ostris/ai-toolkit
One training suite for fine-tuning image, video, and audio diffusion
It wraps the fragmented ecosystem of diffusion training scripts into one configurable CLI and web UI.
Velocity · 7d
+13
★ / day
Trend
↗accelerating
star history
What it does
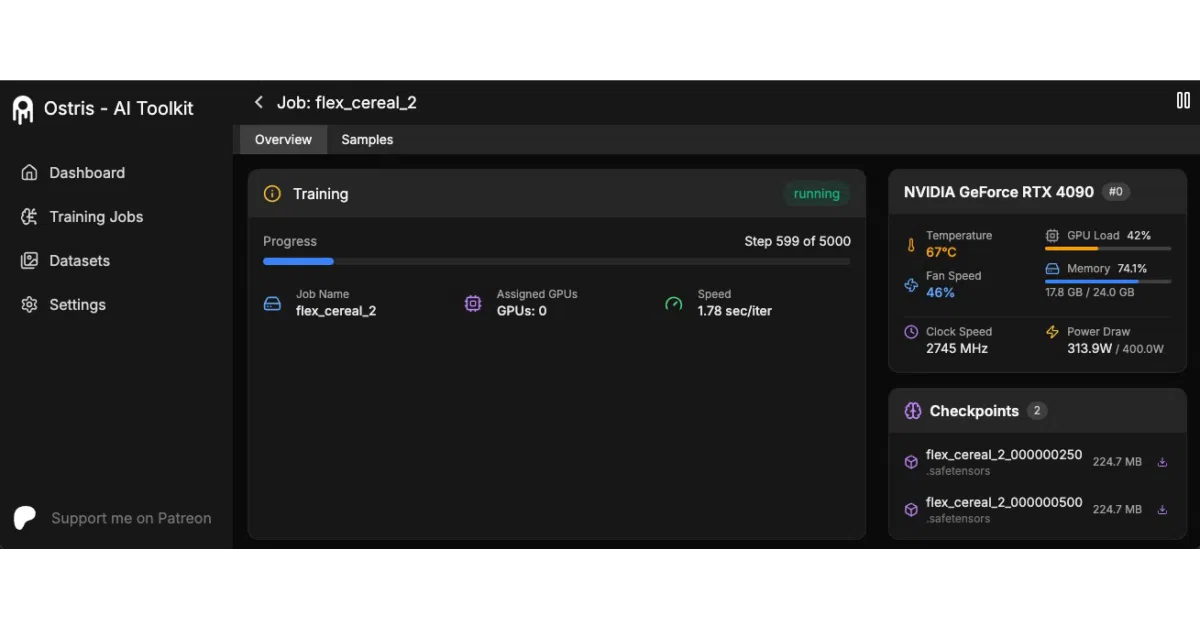
AI Toolkit is a single training suite for fine-tuning diffusion models across image, video, and audio. It supports architectures from FLUX and Stable Diffusion to Wan video and Ace Step audio, offering both a web dashboard and a CLI. The loader automatically buckets mixed aspect ratios, so you can feed it raw images without cropping or resizing.
The interesting bit
The project treats model support like a collector’s challenge, covering image generation, instruction editing, video, and audio under one roof. The author explicitly targets consumer-grade GPUs alongside cloud-ready templates for Modal and RunPod.
Key highlights
- Supports image (FLUX.1/2, SDXL, HiDream), video (Wan 2.1/2.2, LTX-2), instruction/edit, and audio diffusion models.
- Includes a web dashboard for monitoring jobs and a separate Gradio UI for simpler LoRA training.
- Automatically buckets varying image aspect ratios; no manual cropping or resizing needed.
- Can resume training from the last checkpoint after an interruption.
- Experimental macOS support for Apple Silicon, though the author notes it is not fully tested.
Caveats
- Dataset support is limited to JPG, JPEG, and PNG; WebP currently has issues.
- macOS support is experimental and untested on high-RAM configurations.
- Interrupting a checkpoint save can corrupt it.
Verdict
Developers who want to fine-tune modern diffusion models without maintaining a zoo of separate repositories will find this useful. If you only ever train one specific model and already have a working pipeline, the extra abstraction may not be worth the switch.
Frequently asked
- What is ostris/ai-toolkit?
- It wraps the fragmented ecosystem of diffusion training scripts into one configurable CLI and web UI.
- Is ai-toolkit open source?
- Yes — ostris/ai-toolkit is open source, released under the MIT license.
- What language is ai-toolkit written in?
- ostris/ai-toolkit is primarily written in Python.
- How popular is ai-toolkit?
- ostris/ai-toolkit has 11.4k stars on GitHub and is currently accelerating.
- Where can I find ai-toolkit?
- ostris/ai-toolkit is on GitHub at https://github.com/ostris/ai-toolkit.