openvinotoolkit/model_server
Intel's inference server that speaks OpenAI, KServe, and TensorFlow
A C++ model server built for Intel hardware that exposes multiple API dialects so clients don't need to know what backend runs their inference.
Not currently ranked — collecting fresh signals.
star history
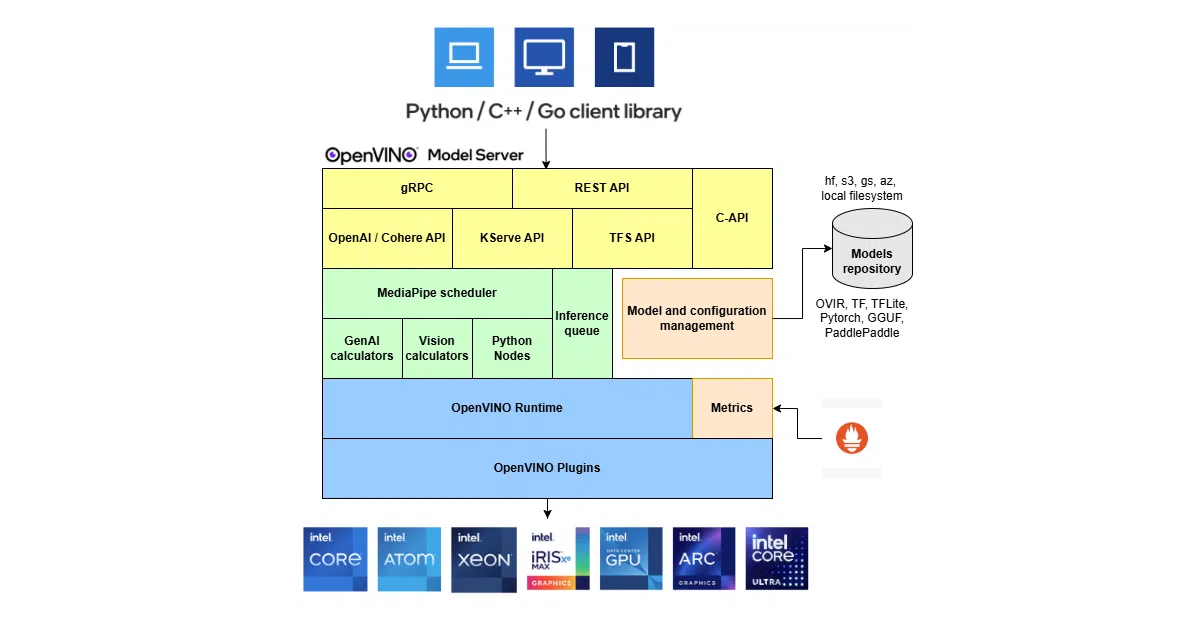
What it does
OpenVINO Model Server (OVMS) hosts ML models and serves inference over gRPC or REST. Clients send requests; the server runs inference via OpenVINO and returns results. It targets Docker, bare metal, and Kubernetes deployments with horizontal and vertical scaling.
The interesting bit
The generative API compatibility is the real pivot: it exposes OpenAI-style endpoints for LLMs, embeddings, reranking, image generation, and now speech tasks, plus KServe and TensorFlow Serving protocols. That’s a lot of API surface for a C++ server optimized around Intel’s inference stack. The DAG scheduler and MediaPipe graph support also let you chain preprocessing, custom nodes, and model execution without leaving the server.
Key highlights
- OpenAI-compatible endpoints for text generation, embeddings, image generation, and speech (new)
- KServe and TensorFlow Serving APIs for traditional model serving
- C++ implementation, Intel-architecture optimized
- Model versioning and runtime config updates without restarts
- Prometheus-compatible metrics
- Supports TensorFlow, PaddlePaddle, ONNX, and AI accelerators
- Windows, Ubuntu, and RedHat tested; Docker images on Docker Hub and RedHat catalog
Caveats
- The README notes testing on specific platforms but doesn’t detail performance characteristics versus other servers
- “Efficient resource utilization” is claimed but no specific benchmarks or comparisons are included in the README itself
Verdict
Worth evaluating if you’re already in the Intel/OpenVINO ecosystem or need a single server that exposes OpenAI-style APIs without the usual Python serving stack. Less compelling if you’re committed to GPU-centric inference or non-Intel hardware.
Frequently asked
- What is openvinotoolkit/model_server?
- A C++ model server built for Intel hardware that exposes multiple API dialects so clients don't need to know what backend runs their inference.
- Is model_server open source?
- Yes — openvinotoolkit/model_server is open source, released under the Apache-2.0 license.
- What language is model_server written in?
- openvinotoolkit/model_server is primarily written in C++.
- How popular is model_server?
- openvinotoolkit/model_server has 905 stars on GitHub.
- Where can I find model_server?
- openvinotoolkit/model_server is on GitHub at https://github.com/openvinotoolkit/model_server.