openai/CLIP
Classify images by describing them, zero-shot
CLIP learns shared image-text representations so you can label photos with natural language instead of curated datasets.
Velocity · 7d
+7.6
★ / day
Trend
→steady
star history
What it does
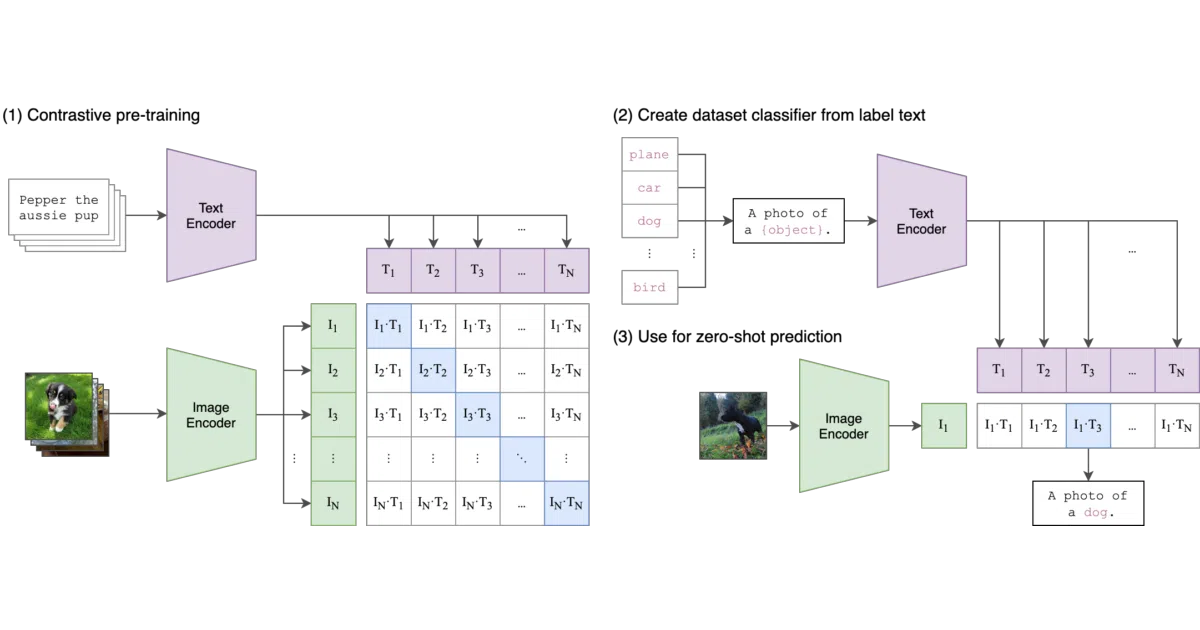
CLIP is a neural network trained on diverse image-text pairs. It predicts which text snippet best matches a given image, letting you perform zero-shot classification by simply writing prompts like “a photo of a snake.” The README notes that it matches the original ResNet50’s zero-shot performance on ImageNet without using any of the dataset’s 1.28 million labeled examples.
The interesting bit
Rather than optimizing for fixed visual categories, CLIP learns a joint embedding space where images and captions are directly comparable. This means you can repurpose the same pretrained weights for new domains just by rewriting the prompt—an approach the authors compare to the zero-shot behavior of GPT-2 and GPT-3.
Key highlights
- Performs zero-shot prediction by scoring cosine similarity between image and text features
- Provides
encode_image()andencode_text()for extracting reusable embeddings in custom pipelines - Includes an example of linear-probe evaluation with scikit-learn on frozen features
- Supports multiple architectures (including ViT-B/32) with automatic weight downloads
- OpenCLIP and Hugging Face implementations are noted for larger models or easier integration
Verdict
Grab it if you want flexible image understanding without curating a dataset. If your task is narrow and your labels are already pristine, bringing a language model into the loop is probably overkill.
Frequently asked
- What is openai/CLIP?
- CLIP learns shared image-text representations so you can label photos with natural language instead of curated datasets.
- Is CLIP open source?
- Yes — openai/CLIP is open source, released under the MIT license.
- What language is CLIP written in?
- openai/CLIP is primarily written in Jupyter Notebook.
- How popular is CLIP?
- openai/CLIP has 34k stars on GitHub and is currently holding steady.
- Where can I find CLIP?
- openai/CLIP is on GitHub at https://github.com/openai/CLIP.