onejune2018/Awesome-LLM-Eval
An awesome list that catalogs LLM eval like human traits
A curated directory of LLM evaluation resources that serves as the living companion to a survey paper on anthropomorphic benchmarking.
Not currently ranked — collecting fresh signals.
star history
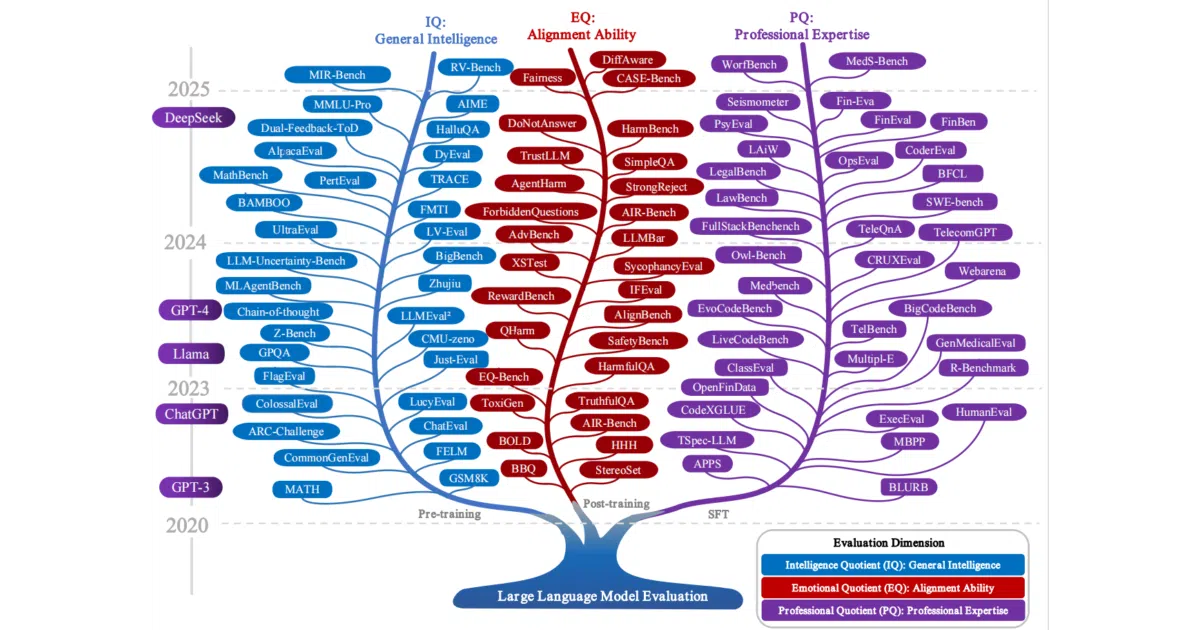
What it does Awesome-LLM-Eval is a curated markdown index of tools, datasets, benchmarks, demos, leaderboards, papers, and models for evaluating large language models and exploring the boundaries of generative AI. It functions as the official, continuously updated companion to the survey Beyond Benchmark: LLMs Evaluation with an Anthropomorphic and Value-oriented Roadmap, because arXiv preprints do not refresh. The list spans general knowledge tests, RAG evaluators, coding challenges, inference-speed benchmarks, and more.
The interesting bit
Rather than dumping links alphabetically, the project added an Anthropomorphic-Taxonomy section that classifies benchmarks by human-like dimensions—starting with an IQ-oriented view of general intelligence—turning a standard awesome-list into a conceptual map of what we are actually measuring when we score a model.
Key highlights
- Covers the full eval stack: tools, datasets, leaderboards, papers, training frameworks, and model lists.
- Includes niche categories often missing from similar indices, such as
RAG-Evaluation,Inference-Speed,Quantization-and-Compression, andAgent-Capabilities. - Maintains bilingual docs (English and Chinese) and a chronological news log tracking additions since 2023.
- Acknowledges contributors in-repo and positions itself as the paper’s real-time successor.
Caveats
- The readme is a dense, table-heavy reference; browsing beyond the table of contents requires patience.
- The anthropomorphic taxonomy is only partially visible in the provided sources; the IQ table is shown, but the full scope of value-oriented dimensions is cut off by the truncation.
Verdict Use this if you are assembling an evaluation suite, writing a survey, or simply want a panoramic snapshot of what the LLM benchmarking world is currently obsessing over. Avoid it if you need a searchable database or interactive tooling—this is strictly a curated reading list.
Frequently asked
- What is onejune2018/Awesome-LLM-Eval?
- A curated directory of LLM evaluation resources that serves as the living companion to a survey paper on anthropomorphic benchmarking.
- Is Awesome-LLM-Eval open source?
- Yes — onejune2018/Awesome-LLM-Eval is open source, released under the MIT license.
- How popular is Awesome-LLM-Eval?
- onejune2018/Awesome-LLM-Eval has 652 stars on GitHub.
- Where can I find Awesome-LLM-Eval?
- onejune2018/Awesome-LLM-Eval is on GitHub at https://github.com/onejune2018/Awesome-LLM-Eval.