nv-tlabs/LLaMA-Mesh
Your chatbot now speaks fluent triangle
An LLM that generates 3D meshes by treating vertex coordinates as plain text, no special tokenizer required.
Not currently ranked — collecting fresh signals.
star history
What it does
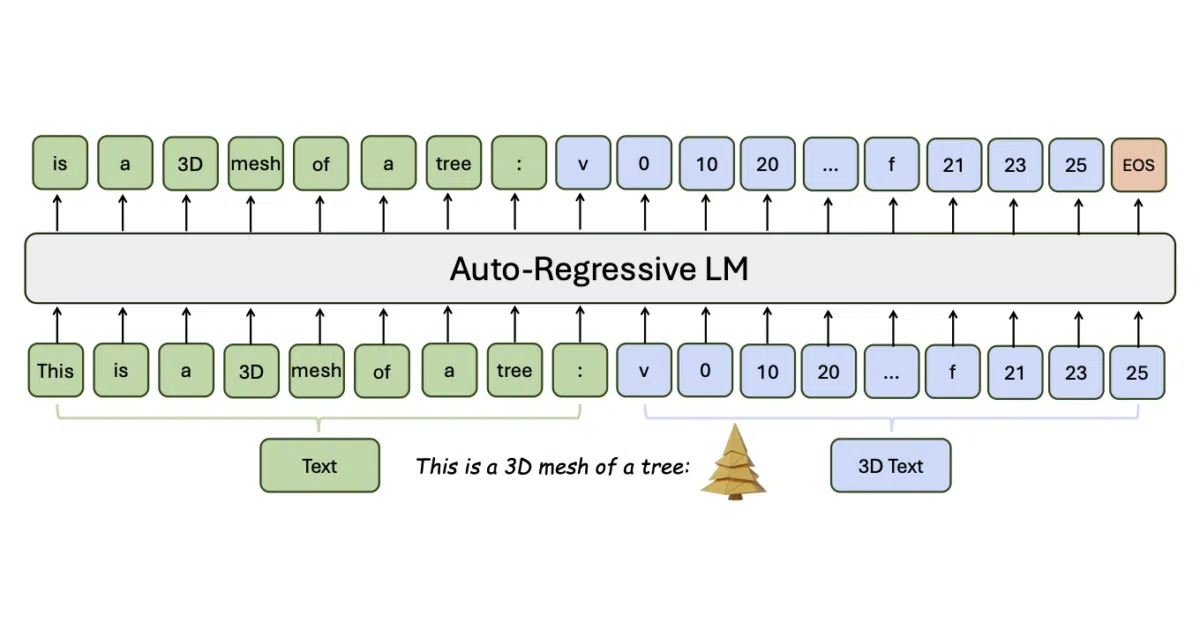
LLaMA-Mesh fine-tunes a pretrained LLM to generate 3D meshes from text prompts, output interleaved text and mesh data, and interpret existing meshes. It runs through a Gradio UI, standard Hugging Face transformers inference, or a Blender addon. The trick is representing vertex coordinates and face definitions as ordinary text tokens rather than inventing a new vocabulary.
The interesting bit
The authors claim this is the first demonstration that LLMs can acquire complex spatial knowledge for 3D generation while staying in a text-based format—and that the model keeps its original text-generation abilities intact. No multimodal architecture surgery; just numbers treated as words.
Key highlights
- Mesh data encoded as plain text (vertex coordinates + face definitions), no vocabulary expansion needed
- Supports conversational generation: text prompts → 3D meshes, or interleaved text/mesh outputs
- Includes mesh understanding/interpretation capabilities, not just generation
- Available via Hugging Face demo,
transformersAPI, and a community Blender addon - Training dataset not yet released (still on the TODO list)
Caveats
- Training dataset remains unreleased, so full reproducibility is pending
- The README is light on quantitative benchmarks; “on par with models trained from scratch” is stated but unsourced here
Verdict
Worth a spin if you’re building generative 3D tools or probing how far text-token reasoning can stretch. Skip it if you need production-grade mesh quality guarantees or training-data transparency today.
Frequently asked
- What is nv-tlabs/LLaMA-Mesh?
- An LLM that generates 3D meshes by treating vertex coordinates as plain text, no special tokenizer required.
- Is LLaMA-Mesh open source?
- Yes — nv-tlabs/LLaMA-Mesh is an open-source project tracked on heatdrop.
- What language is LLaMA-Mesh written in?
- nv-tlabs/LLaMA-Mesh is primarily written in Python.
- How popular is LLaMA-Mesh?
- nv-tlabs/LLaMA-Mesh has 1.2k stars on GitHub.
- Where can I find LLaMA-Mesh?
- nv-tlabs/LLaMA-Mesh is on GitHub at https://github.com/nv-tlabs/LLaMA-Mesh.