noonghunna/club-3090
One RTX 3090, three inference engines, and a lot of VRAM math
Community recipes for serving modern LLMs on RTX 3090s without the usual quantization guesswork.
Velocity · 7d
+10
★ / day
Trend
↗accelerating
star history
What it does
club-3090 is a curated set of Docker Compose recipes, shell helpers, and benchmarked configs for running modern LLMs on one or two RTX 3090s, with cross-rig support for 4090s and 5090s. It wraps vLLM, llama.cpp, and ik_llama into hardware-aware profiles that expose an OpenAI-compatible API on localhost:8020, currently validated for Qwen3.6-27B, Qwen3.6-35B-A3B, Gemma 4 31B, and Gemma 4 26B-A4B.
The interesting bit
The project treats GPU memory as a hard constraint and builds around it. It documents real failure modes—like vLLM’s “Cliff 2” prefill OOM beyond ~50K tokens on a single 24 GB card—and offers explicit workarounds, such as switching to dual-card tensor parallelism or falling back to llama.cpp. There’s even a pull helper that evaluates arbitrary Hugging Face Safetensors repos against the repo’s KV math and gives an honest “will it fit” verdict.
Key highlights
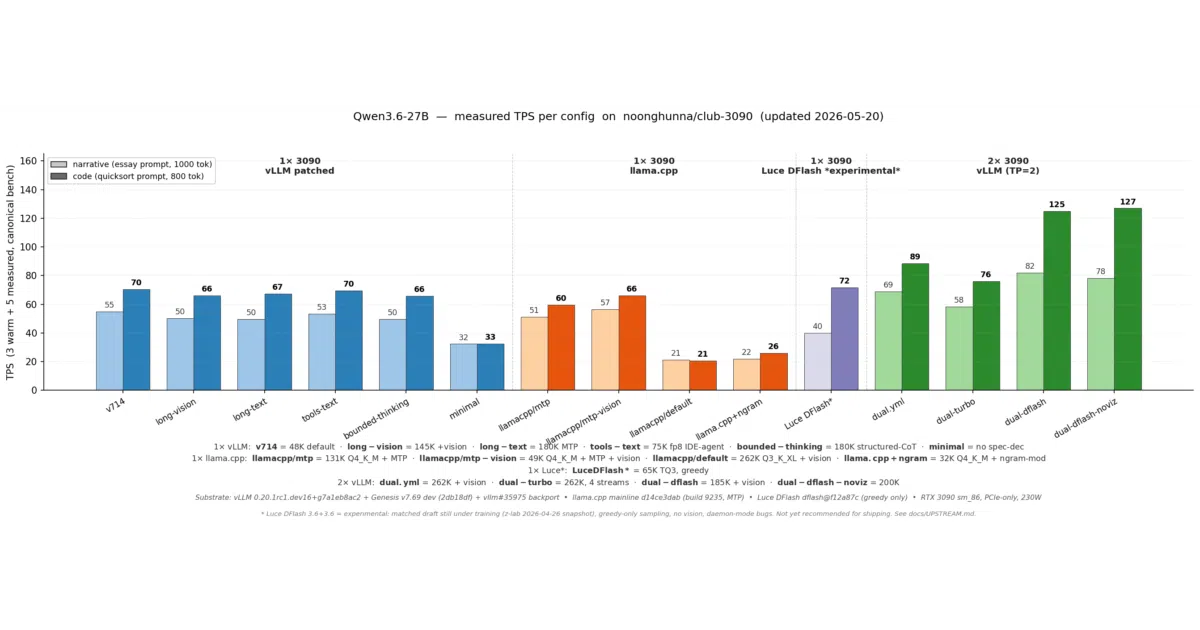
- Multi-engine support: vLLM for throughput (up to 127 code TPS with DFlash), llama.cpp for stability (200K context on a single 3090 without prefill cliffs), and ik_llama for lean GGUF quants.
- Model-agnostic structure with per-model deep dives, measured TPS numbers, and stress-test results including needle-ladder, tool-call correctness, and soak tests.
- Class-aware configs for 4090 and 5090 owners, with documented gotchas like tighter idle VRAM on the 4090 and the 5090’s 32 GB envelope.
- A “Universal
pull” flow that can evaluate any HF Safetensors repo and, on hard blocks, submit redacted diagnostics back to the project.
Caveats
- Single-card vLLM long-context is genuinely broken for >~50K prefill on 24 GB Ampere; the README calls this an open issue and steers you toward llama.cpp or a second GPU.
- Native Windows is unsupported outside of WSL2; only the upstream llama.cpp binary works natively on Windows.
- Some newer models need community forks: Gemma 4 on single-card Ampere requires a patched
beellama.cppbuild because mainline llama.cpp and vLLM hit ahead_dim=512FlashAttention wall.
Verdict Grab this if you have a 3090 (or 4090/5090) sitting idle and want a local dev backend or homelab LLM server with reproducible benchmarks. Skip it if you’re looking for a cloud-native or managed solution—this is unapologetically bare-metal consumer GPU territory.
Frequently asked
- What is noonghunna/club-3090?
- Community recipes for serving modern LLMs on RTX 3090s without the usual quantization guesswork.
- Is club-3090 open source?
- Yes — noonghunna/club-3090 is open source, released under the Apache-2.0 license.
- What language is club-3090 written in?
- noonghunna/club-3090 is primarily written in Python.
- How popular is club-3090?
- noonghunna/club-3090 has 1.8k stars on GitHub and is currently accelerating.
- Where can I find club-3090?
- noonghunna/club-3090 is on GitHub at https://github.com/noonghunna/club-3090.