mosecorg/mosec
Rust-powered serving for Python ML models
Mosec wraps your PyTorch/JAX/TensorFlow model in a Rust async web layer, handling dynamic batching and CPU/GPU pipelines without rewriting your inference code.
Not currently ranked — collecting fresh signals.
star history
What it does
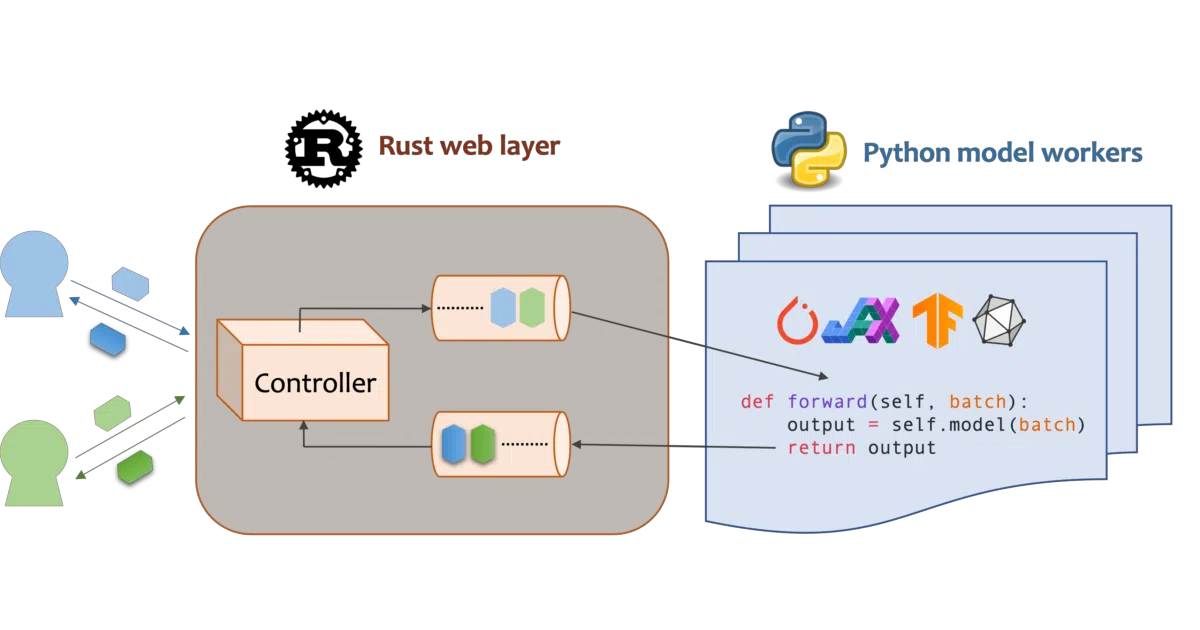
Mosec is a model serving framework that lets you expose ML models as HTTP APIs. You write a Python class with a forward method; Mosec handles the web server, request batching, multi-stage pipelines, and process management. The web layer and task coordination are Rust underneath, but the user interface stays purely Python.
The interesting bit
The dynamic batching is the quietly important part: it accumulates requests up to a max_batch_size or a max_wait_time timeout, then runs batched inference and distributes results back. This is where throughput gains actually come from, and Mosec makes it a single constructor argument rather than a custom queueing system you build yourself.
Key highlights
- Rust async I/O for the web layer; Python for model code — no rewrite required
- Dynamic batching with configurable batch size and wait timeout
- Multi-stage pipelines for CPU/GPU/IO mixed workloads via inter-process communication
- Built-in model warmup, graceful shutdown, and Prometheus metrics
- Supports msgpack, JSON, or custom serialization via mixins
- OpenAPI docs auto-generated from type annotations
Caveats
- Linux and macOS only; no Windows support mentioned
- GPU memory management is still your problem — the README explicitly warns to “make sure inference with the
max_batch_sizevalue won’t cause out-of-memory” - Documentation references are scattered between README, external docs site, and example files
Verdict Worth a look if you’re running Python inference in production and tired of hand-rolling batching logic around FastAPI or Flask. Skip it if you need a managed cloud solution — Mosec is explicitly “do one thing well” on the serving layer, not the infrastructure layer.
Frequently asked
- What is mosecorg/mosec?
- Mosec wraps your PyTorch/JAX/TensorFlow model in a Rust async web layer, handling dynamic batching and CPU/GPU pipelines without rewriting your inference code.
- Is mosec open source?
- Yes — mosecorg/mosec is open source, released under the Apache-2.0 license.
- What language is mosec written in?
- mosecorg/mosec is primarily written in Python.
- How popular is mosec?
- mosecorg/mosec has 904 stars on GitHub.
- Where can I find mosec?
- mosecorg/mosec is on GitHub at https://github.com/mosecorg/mosec.