mit-han-lab/proxylessnas
Neural architecture search that skips the proxy and talks to hardware directly
ProxylessNAS searches CNN architectures on your actual target task and device, not a stand-in dataset or simulator.
Not currently ranked — collecting fresh signals.
star history
What it does
ProxylessNAS generates specialized neural network architectures for specific hardware platforms—CPU, GPU, or mobile—without using proxy tasks or simplified search spaces. It provides pre-trained PyTorch and TensorFlow models you can load in two lines via PyTorch Hub, plus code to run the full architecture search yourself.
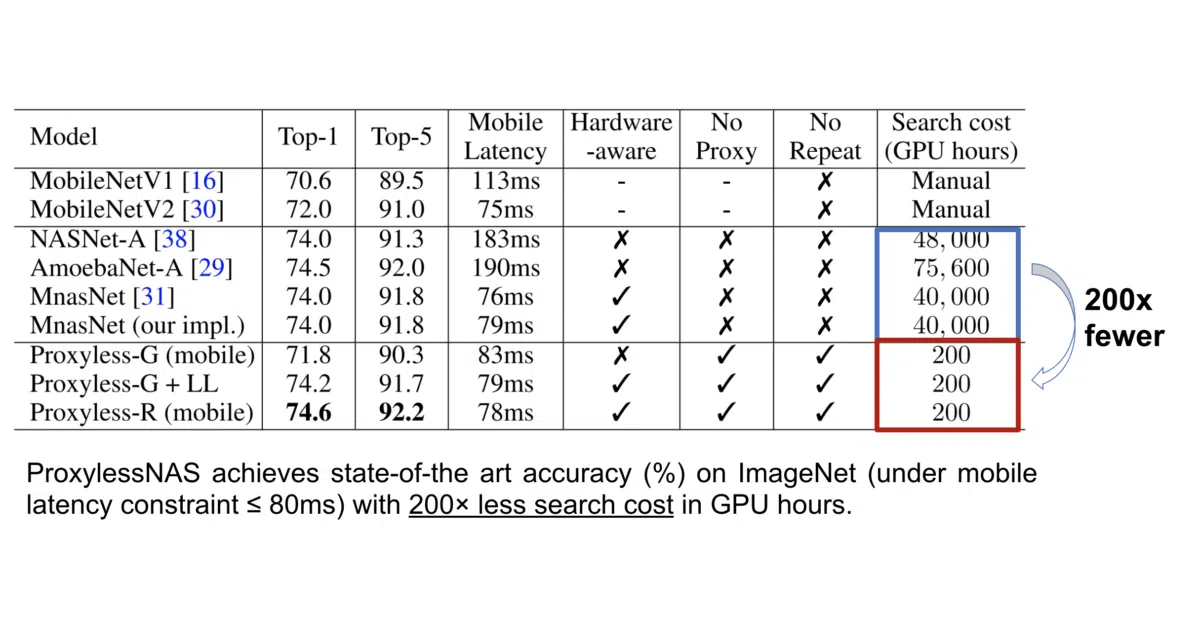
The interesting bit
The core pitch is specialization over generalization: instead of deploying one model everywhere and hoping, it treats latency on the actual target device as a first-class citizen during search. The README is refreshingly blunt about this—“People used to deploy one model to all platforms, but this is not good.”
Key highlights
- Pre-trained variants:
proxyless_cpu,proxyless_gpu,proxyless_mobile,proxyless_mobile_14, andproxyless_cifar - GPU-optimized model hits 75.1% ImageNet top-1 at 5.1ms latency—3.1 points better than MobileNetV2 and 20% faster per the README’s table
- First place in CVPR 2019 Visual Wake Words Challenge (TF-lite track); third place in LPIRC classification
- Integrated into PyTorch Hub, Microsoft NNI, and Amazon AutoGluon
- Includes a visualization of the search process
Caveats
- The repo language is tagged C++ but the visible code and usage are overwhelmingly Python; the C++ footprint is unclear
- Manual Google Drive fallback required if automatic pre-trained weight downloads fail
- Search code is provided, but hardware requirements and search time are not specified in the README
Verdict
Worth a look if you’re shipping CV models to resource-constrained devices and tired of hand-tuning MobileNet variants. Less relevant if you’re running everything on A100s or already locked into a different NAS pipeline.
Frequently asked
- What is mit-han-lab/proxylessnas?
- ProxylessNAS searches CNN architectures on your actual target task and device, not a stand-in dataset or simulator.
- Is proxylessnas open source?
- Yes — mit-han-lab/proxylessnas is open source, released under the MIT license.
- What language is proxylessnas written in?
- mit-han-lab/proxylessnas is primarily written in C++.
- How popular is proxylessnas?
- mit-han-lab/proxylessnas has 1.4k stars on GitHub.
- Where can I find proxylessnas?
- mit-han-lab/proxylessnas is on GitHub at https://github.com/mit-han-lab/proxylessnas.