mit-han-lab/gan-compression
Shrink your GAN without the retraining treadmill
A once-for-all student generator lets you extract compressed models on demand, no retraining required.
Not currently ranked — collecting fresh signals.
star history
What it does
GAN Compression takes bloated conditional GANs—pix2pix, CycleGAN, GauGAN, MUNIT—and trims them down for actual deployment. The repo claims 9–21× computation reduction and 4.6–33× model size shrinkage while keeping visual fidelity intact. It also ships a TVM-tuned interactive demo that hits 8 FPS on a Jetson Nano, which is the difference between “works in the lab” and “works in someone’s hand.”
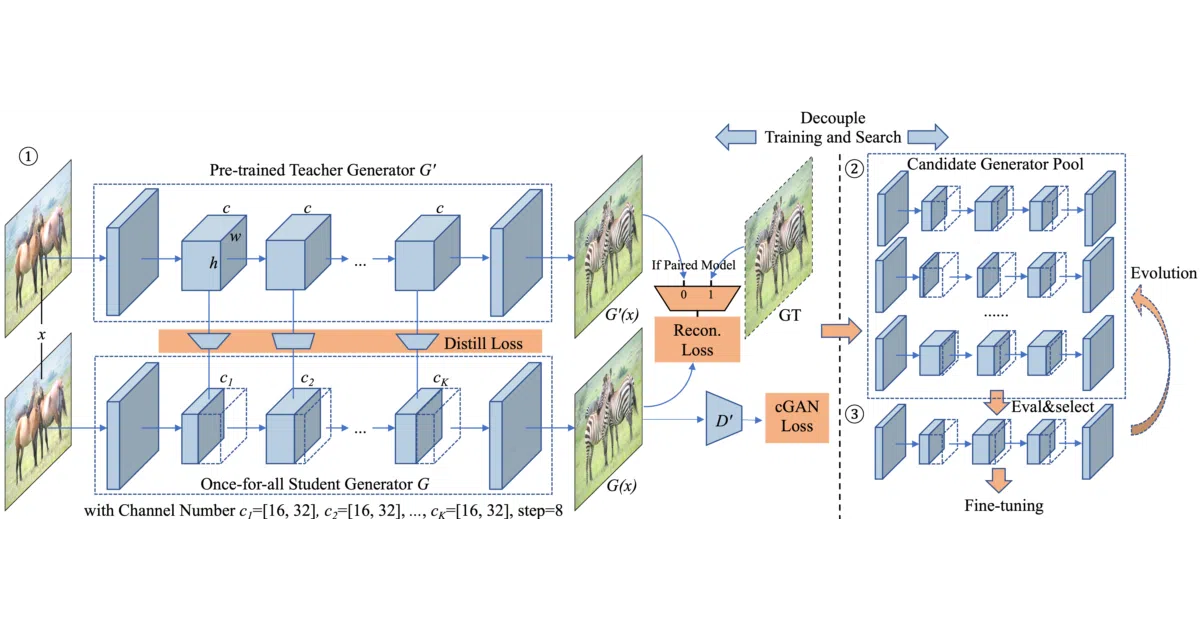
The interesting bit
The trick is a “once-for-all” student generator trained via distillation with weight sharing across all possible channel counts. After that one training run, you extract sub-generators at different widths and evaluate them without retraining—then pick your sweet spot between speed and quality. It’s basically a buffet where you decide the portion size after cooking the whole meal.
Key highlights
- Supports pix2pix, CycleGAN, GauGAN, and MUNIT (multimodal unsupervised translation)
- Includes pre-trained compressed models with shell scripts for testing and latency measurement
- Interactive demo with TVM optimization for edge GPUs (Jetson Nano at 8 FPS)
- Colab notebooks for CycleGAN and pix2pix to skip the setup slog
- T-PAMI version of the paper available, plus legacy model weights if retrained versions drift from published results
Caveats
- Linux and NVIDIA GPU strongly implied; CPU support exists but this is clearly GPU-targeted
- Dataset prep for Cityscapes and COCO-Stuff is manual and fiddly (license restrictions, extra model downloads for mIoU)
- README notes “a little differences” between retrained and paper models, which is honest but means you may need to fall back to legacy weights
Verdict
Worth a look if you’re trying to ship interactive image-to-image translation on hardware that isn’t a server rack. Skip it if you’re just training GANs for paper figures and don’t care about inference cost.
Frequently asked
- What is mit-han-lab/gan-compression?
- A once-for-all student generator lets you extract compressed models on demand, no retraining required.
- Is gan-compression open source?
- Yes — mit-han-lab/gan-compression is an open-source project tracked on heatdrop.
- What language is gan-compression written in?
- mit-han-lab/gan-compression is primarily written in Python.
- How popular is gan-compression?
- mit-han-lab/gan-compression has 1.1k stars on GitHub.
- Where can I find gan-compression?
- mit-han-lab/gan-compression is on GitHub at https://github.com/mit-han-lab/gan-compression.