mims-harvard/TDC
A standard library for drug-discovery ML, from Harvard
TDC tries to stop every bio-AI team from re-inventing the same data loaders and benchmarks.
Not currently ranked — collecting fresh signals.
star history
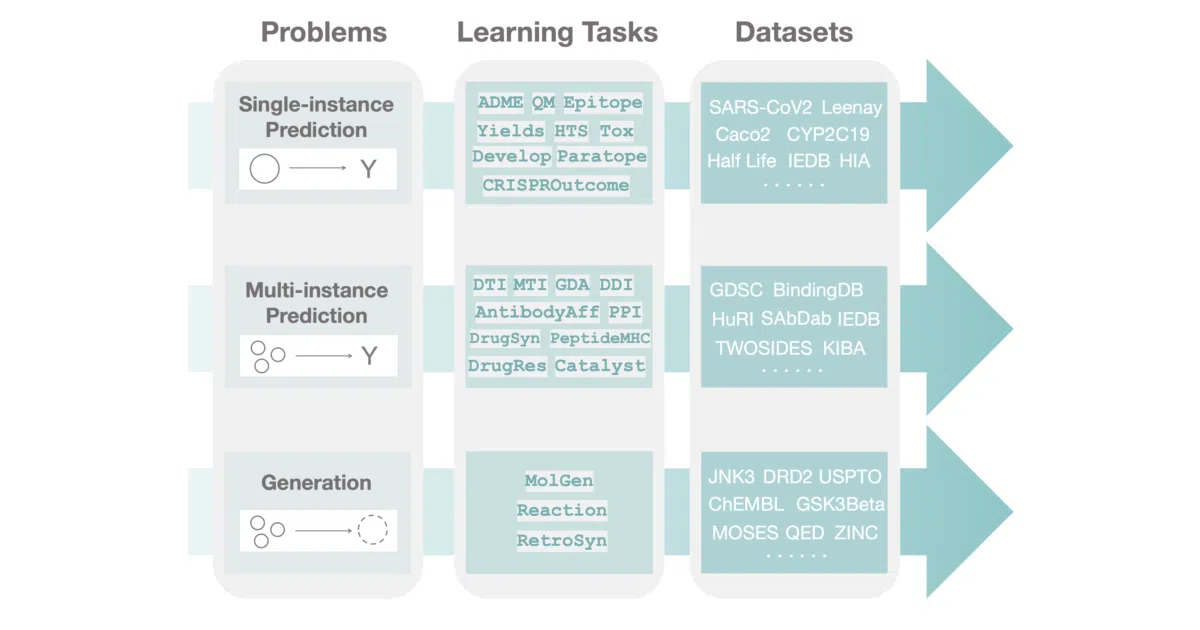
What it does TDC is a Python package that collects datasets, splits, and benchmarks for machine learning in therapeutics. It covers small molecules, antibodies, and vaccines across tasks like target discovery, activity screening, and safety prediction. The API is hierarchical: pick a problem type (single-instance prediction, multi-instance prediction, or generation), then a task, then a dataset. Most datasets load in three lines of code.
The interesting bit The project treats therapeutic ML as an infrastructure problem, not just a modeling problem. By standardizing data splits and evaluation, it attempts to make results comparable across papers that otherwise use incompatible setups. The “scaffold split” example in the README is telling: they care about whether models generalize to genuinely unseen chemical structures, not just random held-out rows.
Key highlights
- Three-line data loading via
PyTDCwith minimal dependencies (numpy, pandas, scikit-learn, etc.) - Covers the full pipeline from target discovery through manufacturing
- Includes molecule generation oracles and benchmark leaderboards
- Three-tier taxonomy: problem → learning task → dataset
- Active since 2020 with papers in NeurIPS and Nature Chemical Biology
Caveats
- Self-described as “beta release”; the README explicitly asks users to upgrade regularly
- Heavy academic footprint (Harvard, Nature, NeurIPS) may mean priorities skew toward publishable benchmarks over production robustness
Verdict Worth a look if you’re doing ML for drug discovery and tired of writing the 47th custom data loader. Probably overkill if you just need one specific molecular property dataset and already have your own splits.
Frequently asked
- What is mims-harvard/TDC?
- TDC tries to stop every bio-AI team from re-inventing the same data loaders and benchmarks.
- Is TDC open source?
- Yes — mims-harvard/TDC is open source, released under the MIT license.
- What language is TDC written in?
- mims-harvard/TDC is primarily written in Jupyter Notebook.
- How popular is TDC?
- mims-harvard/TDC has 1.3k stars on GitHub.
- Where can I find TDC?
- mims-harvard/TDC is on GitHub at https://github.com/mims-harvard/TDC.