mileyan/pseudo_lidar
Faking a $75K sensor with two cameras and a format swap
A CVPR 2019 project shows that stereo cameras can rival LiDAR for 3D object detection—if you stop treating depth like an image.
Not currently ranked — collecting fresh signals.
star history
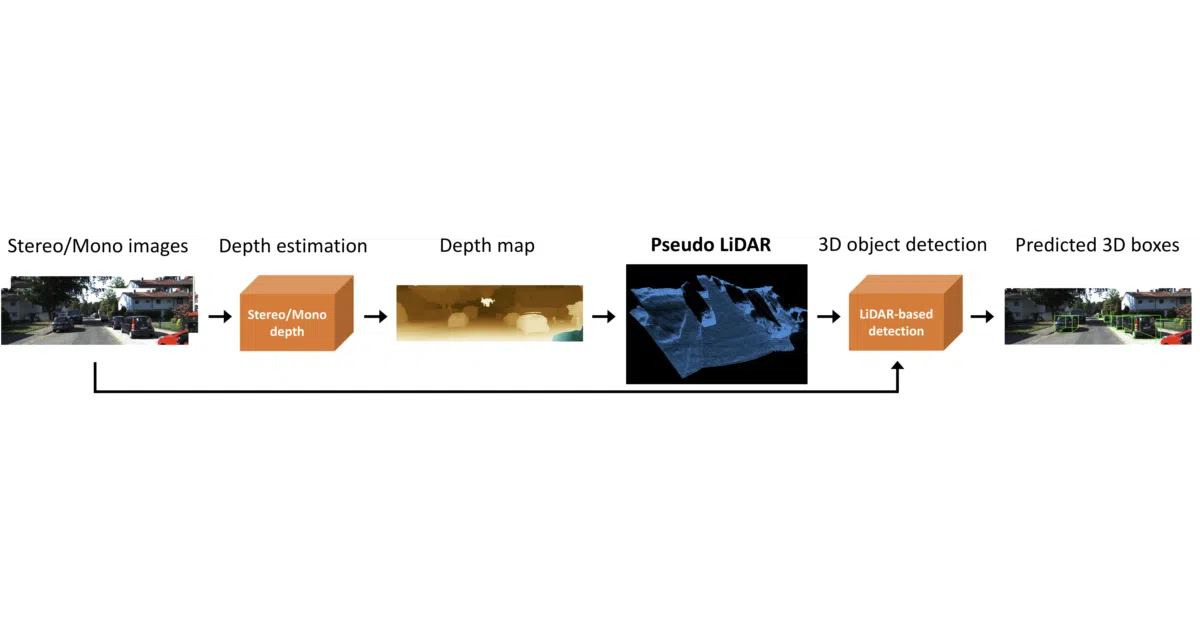
What it does Takes stereo image pairs, estimates depth via PSMNet, then reprojects the depth map into a 3D point cloud that mimics actual LiDAR output. Feeds that “pseudo-LiDAR” into existing LiDAR-based detectors (AVOD, Frustum-PointNets) without touching their architectures. On KITTI, it jumped stereo-based 3D detection from 22% to 74% for objects within 30m—at the time, the top stereo entry on the leaderboard.
The interesting bit The authors argue the gap between cheap cameras and expensive LiDAR isn’t mainly depth quality—it’s representation. Convolutional networks handle dense image-like grids differently than sparse 3D point clouds. So they don’t improve the stereo estimator; they just change the data format to something LiDAR pipelines already expect. It’s a hack in the best sense: let the expensive algorithms do what they’re good at, and trick them into accepting budget input.
Key highlights
- Pre-trained PSMNet model and pre-generated pseudo-LiDAR point clouds available via Google Drive—skip training if you just want to experiment with detection.
- Includes preprocessing scripts for disparity generation, point cloud conversion, and ground plane fitting (RANSAC).
- Supports both stereo disparity and monocular depth maps (DORN-style) via a
--is_depthflag. - Modified AVOD fork (
avod_pl) available separately for end-to-end training. - Jupyter notebook added in 2020 for point cloud visualization.
Caveats
- Setup is involved: KITTI dataset, multiple Python environments, specific folder structures, and external detector codebases (AVOD/Frustum-PointNets) that you patch rather than integrate cleanly.
- Pre-trained detection models are trained on
train.txtonly; leaderboard submission requires retraining ontrainval.txt. - Real Velodyne data still needed as ground truth to train the stereo estimator—you’re not fully escaping LiDAR, just pushing it to the training phase.
Verdict Worth studying if you’re building perception stacks where hardware cost matters (robotics, low-volume vehicles, academic fleets). Less useful if you already have LiDAR, or if you need a drop-in library—this is a research artifact with pipeline glue, not a product. The core insight about representation vs. quality remains relevant even as foundation models advance.
Frequently asked
- What is mileyan/pseudo_lidar?
- A CVPR 2019 project shows that stereo cameras can rival LiDAR for 3D object detection—if you stop treating depth like an image.
- Is pseudo_lidar open source?
- Yes — mileyan/pseudo_lidar is open source, released under the MIT license.
- What language is pseudo_lidar written in?
- mileyan/pseudo_lidar is primarily written in Jupyter Notebook.
- How popular is pseudo_lidar?
- mileyan/pseudo_lidar has 1k stars on GitHub.
- Where can I find pseudo_lidar?
- mileyan/pseudo_lidar is on GitHub at https://github.com/mileyan/pseudo_lidar.