microsoft/LLMLingua
Diet your giant LLM prompts with a tiny language model
LLMLingua uses a small language model to compress prompts and KV-caches by up to 20×, cutting API costs and helping large models retain key details in long contexts.
Not currently ranked — collecting fresh signals.
star history
What it does
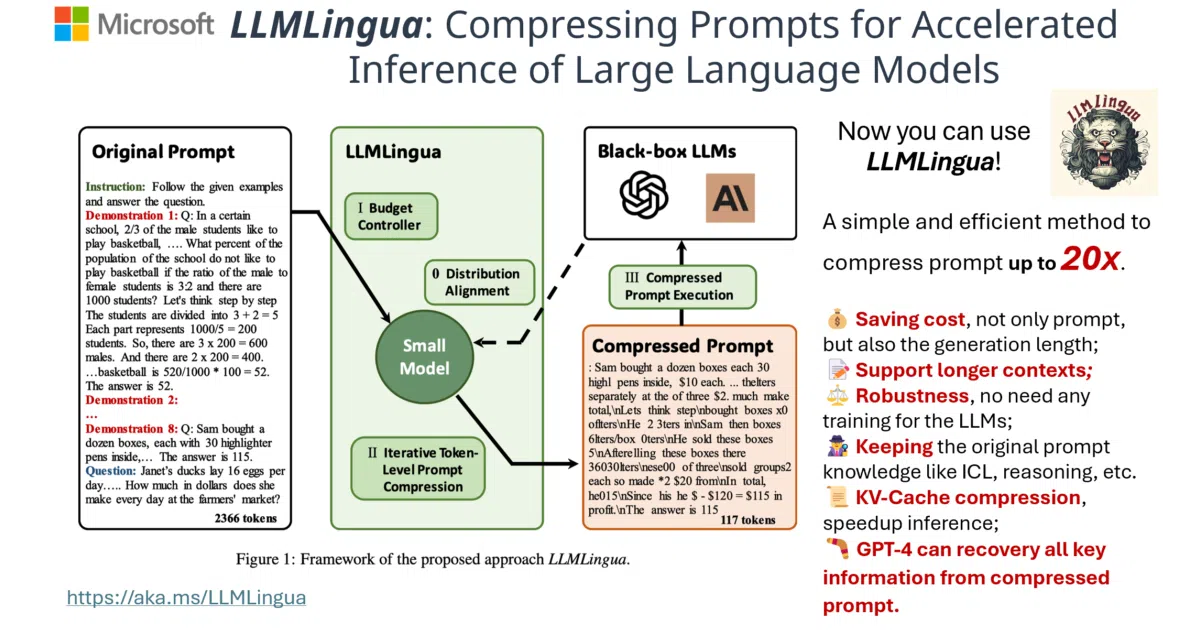
LLMLingua is a family of prompt compression tools that use small, efficient language models—like GPT-2 small or LLaMA-7B—to prune redundant tokens from prompts before they reach an expensive target LLM. The suite includes LLMLingua for general compression, LongLLMLingua for mitigating the “lost in the middle” problem in long contexts, LLMLingua-2 for faster task-agnostic distillation-based compression, and SecurityLingua for detecting jailbreak attacks via security-aware compression. By compressing both the prompt text and the KV-cache, it aims to reduce inference overhead and extend effective context limits.
The interesting bit
The core insight is using a “weaker” model to edit the input of a “stronger” one. LLMLingua-2 takes this further by distilling GPT-4 token importance judgments into a BERT-level encoder, making compression 3×–6× faster than the original method while generalizing better to out-of-domain data. It is a rare case where preprocessing with a cheaper model yields measurable gains in both cost and accuracy for the downstream LLM.
Key highlights
- Claims up to 20× prompt compression with minimal performance loss, according to the README.
- LongLLMLingua specifically targets the “lost in the middle” effect and cites a 21.4% RAG performance improvement using one-quarter of the tokens.
- LLMLingua-2 uses data distillation from GPT-4 and runs 3×–6× faster than the first version.
- Includes SecurityLingua, which applies the same compression logic to reveal malicious intent in jailbreak prompts with reportedly 100× lower token overhead than typical guardrails.
- Integrates with LangChain, LlamaIndex, and Prompt flow; ships with example notebooks for RAG, online meetings, chain-of-thought, and code tasks.
Verdict
Worth a look if you are burning API tokens on long RAG contexts or hitting context-window limits. Probably overkill if your prompts are already short and your inference costs are negligible.
Frequently asked
- What is microsoft/LLMLingua?
- LLMLingua uses a small language model to compress prompts and KV-caches by up to 20×, cutting API costs and helping large models retain key details in long contexts.
- Is LLMLingua open source?
- Yes — microsoft/LLMLingua is open source, released under the MIT license.
- What language is LLMLingua written in?
- microsoft/LLMLingua is primarily written in Python.
- How popular is LLMLingua?
- microsoft/LLMLingua has 6.4k stars on GitHub.
- Where can I find LLMLingua?
- microsoft/LLMLingua is on GitHub at https://github.com/microsoft/LLMLingua.