lucidrains/mmdit
One layer of SD3’s brain, extracted for tinkering
A single, hackable PyTorch block that lets text and image tokens attend to each other, generalized to even more modalities.
Not currently ranked — collecting fresh signals.
star history
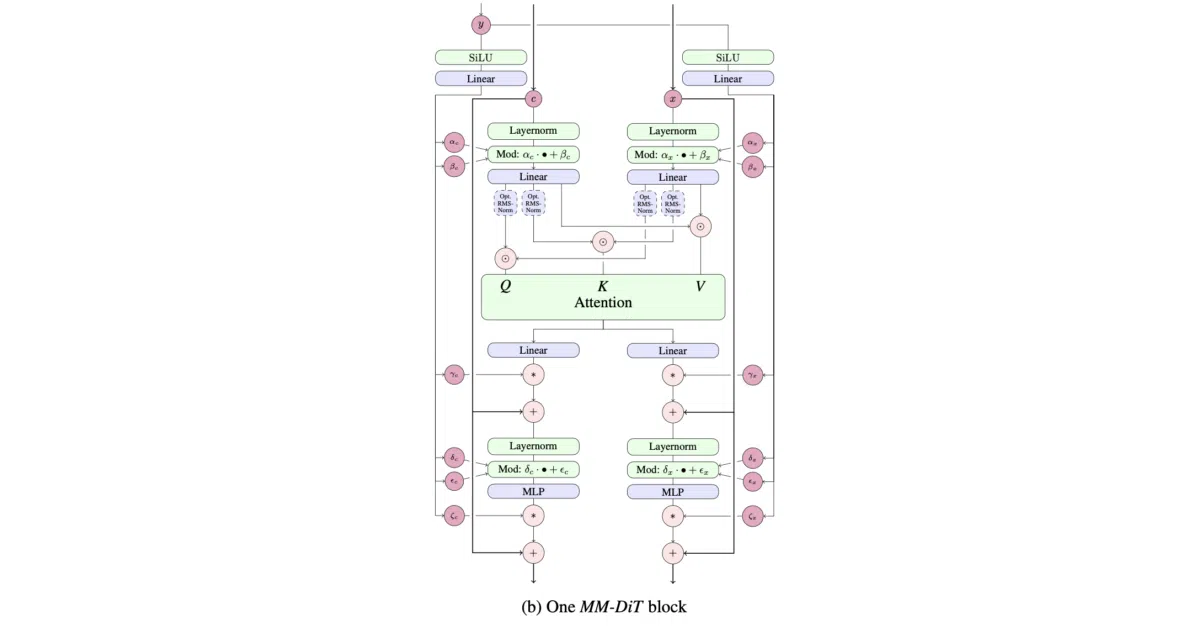
What it does This repo implements the MMDiT block from Stable Diffusion 3—the multi-modal transformer layer that lets text and image tokens attend to each other inside a single diffusion model. It comes as a faithful single-layer reproduction, plus a generalized variant that can juggle three or more token streams (think audio or video dropped into the same mix).
The interesting bit The code is deliberately not a full diffusion pipeline; it is low-level plumbing meant for grafting onto larger experiments. The author also tosses in an improvised adaptive self-attention variant that uses learned gating to pick attention weights, an idea borrowed from GigaGAN’s adaptive convolutions. It saves you from re-typing the SD3 paper yourself.
Key highlights
- Faithful PyTorch reproduction of the MMDiT layer from the SD3 paper
- Generalized to more than two modalities in a single attention pass
- Includes an experimental adaptive attention layer with learned gating
- Clean, modular API: drop a
MMDiTBlockbetween your own encoder and decoder stacks
Caveats
- Not a complete trainable diffusion model; you bring the noise schedule, VAE, and training loop
- The adaptive attention is described as “improvised,” so treat it as experimental
- The generalized multi-modal stack is the author’s own extension beyond the paper
Verdict Grab it if you are building or ablating a custom multi-modal diffusion model and need a well-written reference block. Skip it if you want a ready-to-run Stable Diffusion 3 replacement.
Frequently asked
- What is lucidrains/mmdit?
- A single, hackable PyTorch block that lets text and image tokens attend to each other, generalized to even more modalities.
- Is mmdit open source?
- Yes — lucidrains/mmdit is open source, released under the MIT license.
- What language is mmdit written in?
- lucidrains/mmdit is primarily written in Python.
- How popular is mmdit?
- lucidrains/mmdit has 552 stars on GitHub.
- Where can I find mmdit?
- lucidrains/mmdit is on GitHub at https://github.com/lucidrains/mmdit.