logpai/loglizer
Academic log anomaly detection, batteries semi-included
A research toolkit that wires classic ML models to parsed system logs so you can benchmark anomaly detectors without building the plumbing from scratch.
Not currently ranked — collecting fresh signals.
star history
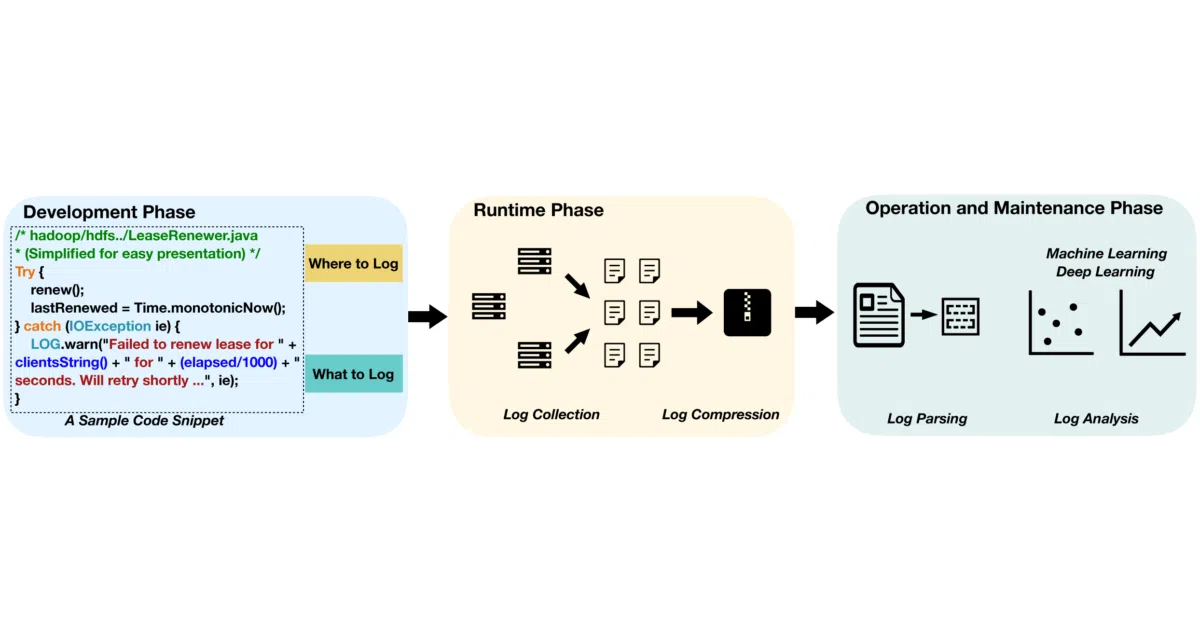
What it does Loglizer implements a standard pipeline for log-based anomaly detection: parse unstructured logs into structured events, slice them into sequences via sliding or session windows, vectorize the sequences, then train classifiers to flag anomalies. It ships with implementations of nine models—supervised (LR, Decision Tree, SVM) and unsupervised (PCA, Isolation Forest, LOF, One-Class SVM, Invariants Mining, Clustering)—plus benchmark numbers on an HDFS dataset.
The interesting bit The value is less the models themselves than the wiring. The authors, who won an ISSRE Most Influential Paper for this work, have already done the tedious work of connecting log parsing, feature extraction, and model evaluation so researchers can compare techniques on common ground. Think of it as a reference implementation with citations attached.
Key highlights
- Nine ML models with direct paper references and provenance (Microsoft, IBM, Intel, etc.)
- Benchmark F1 scores published for HDFS: Decision Tree hits 0.998, Invariants Mining 0.915, PCA a weaker 0.769
- Explicit pipeline stages: log collection → parsing → feature extraction → detection
- Companion logparser and loghub projects for parsing and datasets
- API follows familiar scikit-learn patterns:
fit_transform,fit,predict
Caveats
- Two advertised models (DeepLog, AutoEncoder) are marked “coming” with no visible timeline
- README warns that “all ML models are not magic” and parameter tuning is on you
- Using your own logs requires rewriting the dataloader; the built-in path assumes HDFS
- Last major restructure was February 2019; activity level is unclear
Verdict Grab this if you’re writing a paper on AIOps and need a reproducible baseline to beat. Skip it if you want production-ready log monitoring—this is research scaffolding, not a deployed system.
Frequently asked
- What is logpai/loglizer?
- A research toolkit that wires classic ML models to parsed system logs so you can benchmark anomaly detectors without building the plumbing from scratch.
- Is loglizer open source?
- Yes — logpai/loglizer is open source, released under the MIT license.
- What language is loglizer written in?
- logpai/loglizer is primarily written in Jupyter Notebook.
- How popular is loglizer?
- logpai/loglizer has 1.4k stars on GitHub.
- Where can I find loglizer?
- logpai/loglizer is on GitHub at https://github.com/logpai/loglizer.