leptonai/search_with_lepton
Perplexity in a Python file: the 500-line search demo
A minimal, deployable conversational search engine that wires an LLM to Bing or Google and wraps it in a pretty UI.
Not currently ranked — collecting fresh signals.
star history
What it does
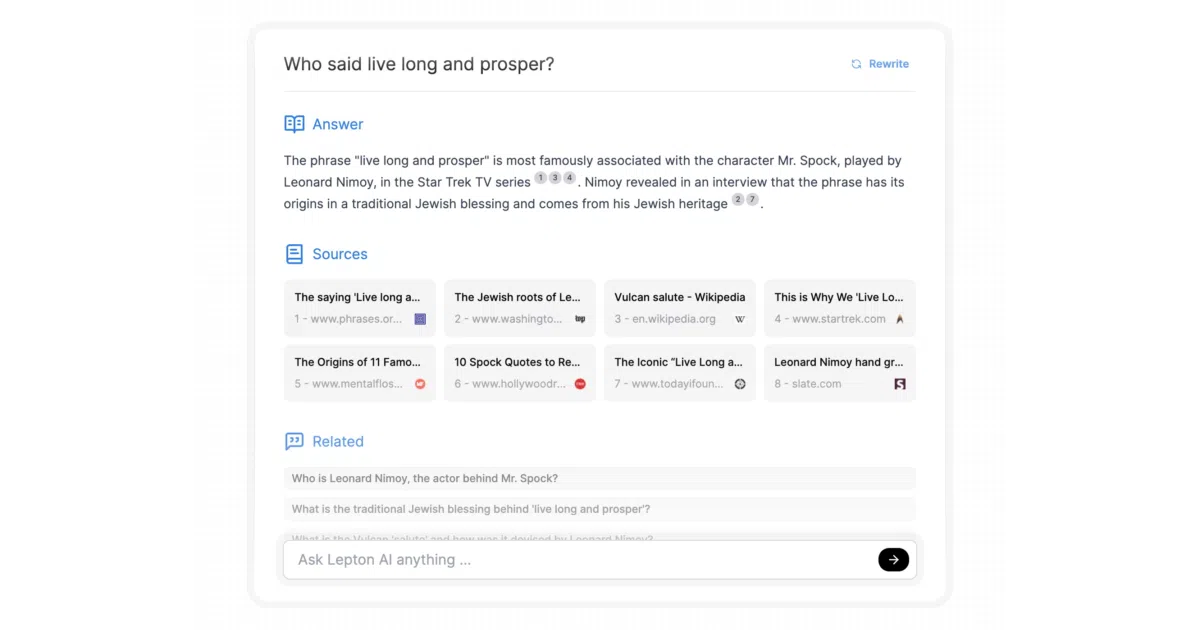
This is a demo application that pairs a search engine backend (Bing or one of three Google options) with an LLM to produce conversational, cited search results. The whole thing ships in under 500 lines of Python, plus a TypeScript frontend. You bring API keys; it brings the wiring and a shareable, cached results page.
The interesting bit
The project is essentially a clean integration layer — search results feed the LLM, the LLM synthesizes answers with citations, and Lepton’s built-in KV store caches everything so links stay shareable. The “less than 500 lines” claim is the real flex: it’s a readable reference implementation, not a framework.
Key highlights
- Supports Bing, SearchApi, Serper, or Google’s Programmable Search Engine
- Built-in LLM and KV caching via Lepton’s platform (OpenAI-compatible)
- One-click deploy to Lepton AI, or run locally with
python search_with_lepton.py - Frontend builds with standard npm tooling; UI is described as “customizable pretty”
- Live demo at search.lepton.run
Caveats
- Requires Lepton AI account and workspace token; the README nudges you toward their platform
- “Less than 500 lines” refers to the Python backend — the TypeScript frontend is separate and uncounted
- Search API keys are on you; no free tier mentioned
Verdict
Good for developers who want to see how search+LLM plumbing works without parsing a SaaS pricing page. Skip it if you need a self-contained, provider-agnostic solution — this demo is quietly selling Lepton’s platform.
Frequently asked
- What is leptonai/search_with_lepton?
- A minimal, deployable conversational search engine that wires an LLM to Bing or Google and wraps it in a pretty UI.
- Is search_with_lepton open source?
- Yes — leptonai/search_with_lepton is open source, released under the Apache-2.0 license.
- What language is search_with_lepton written in?
- leptonai/search_with_lepton is primarily written in TypeScript.
- How popular is search_with_lepton?
- leptonai/search_with_lepton has 8.1k stars on GitHub.
- Where can I find search_with_lepton?
- leptonai/search_with_lepton is on GitHub at https://github.com/leptonai/search_with_lepton.