kvcache-ai/Mooncake
Disaggregating LLM Inference to Stop GPUs From Babysitting KV Cache
Born as Kimi's production serving layer, it separates LLM prefill and decode into distinct clusters and parks the KV cache in a distributed pool of CPU, DRAM, and SSD so GPUs stop wasting memory on context state.
Velocity · 7d
+17
★ / day
Trend
↗accelerating
star history
What it does
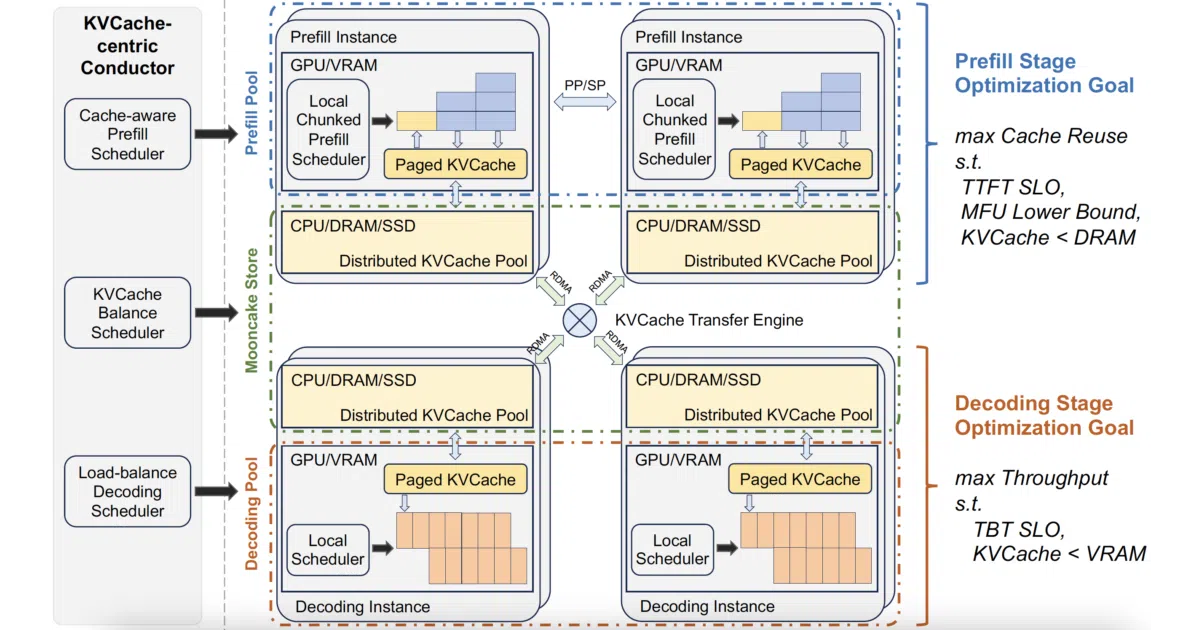
Mooncake is the production serving platform behind Moonshot AI’s Kimi. It implements a KVCache-centric disaggregated architecture that splits prefill and decoding into separate hardware clusters, then parks the resulting KV cache in a distributed pool built from the cluster’s otherwise idle CPUs, DRAM, and SSDs. A scheduler balances throughput against latency SLOs and can predictively reject requests when overloaded.
The interesting bit
Instead of treating GPUs as the only memory tier, Mooncake uses them purely for compute while shuttling KV tensors around via RDMA, CXL, NVMe-over-Fabric, or even TCP through its Transfer Engine. The open-sourced components—the Transfer Engine and Mooncake Store—have already been adopted by vLLM, SGLang, TensorRT-LLM, and LMDeploy, suggesting the industry is converging on this “GPU-as-worker, everything-else-as-storage” model.
Key highlights
- Won Best Paper at FAST 2025; traces and the technical report are included in the repo.
- Transfer Engine supports batched data movement across TCP, RDMA, CXL/shared-memory, and NVMe-over-Fabric with lower I/O latency than Gloo or traditional TCP.
- Under real workloads, Kimi handles 75% more requests; in simulated long-context scenarios, throughput rises up to 525% while still meeting SLOs.
- Mooncake Store and the P2P Store (now released as
checkpoint-engine) provide distributed KV cache and checkpointing; the latter updates a 1T-parameter model across thousands of GPUs in roughly 20 seconds. - Integrated as a backend or connector in vLLM, SGLang, TensorRT LLM, LMDeploy, and others.
Verdict
Infrastructure engineers running vLLM, SGLang, or TensorRT-LLM at scale should evaluate this if GPU memory is the bottleneck. If you are serving small models on a single node, disaggregating prefill and decode is likely overkill.
Frequently asked
- What is kvcache-ai/Mooncake?
- Born as Kimi's production serving layer, it separates LLM prefill and decode into distinct clusters and parks the KV cache in a distributed pool of CPU, DRAM, and SSD so GPUs stop wasting memory on context state.
- Is Mooncake open source?
- Yes — kvcache-ai/Mooncake is open source, released under the Apache-2.0 license.
- What language is Mooncake written in?
- kvcache-ai/Mooncake is primarily written in C++.
- How popular is Mooncake?
- kvcache-ai/Mooncake has 6k stars on GitHub and is currently accelerating.
- Where can I find Mooncake?
- kvcache-ai/Mooncake is on GitHub at https://github.com/kvcache-ai/Mooncake.