kserve/kserve
One Kubernetes platform for both LLMs and classic ML models
KServe tries to stop your infrastructure from splintering every time a new AI framework appears.
Not currently ranked — collecting fresh signals.
star history
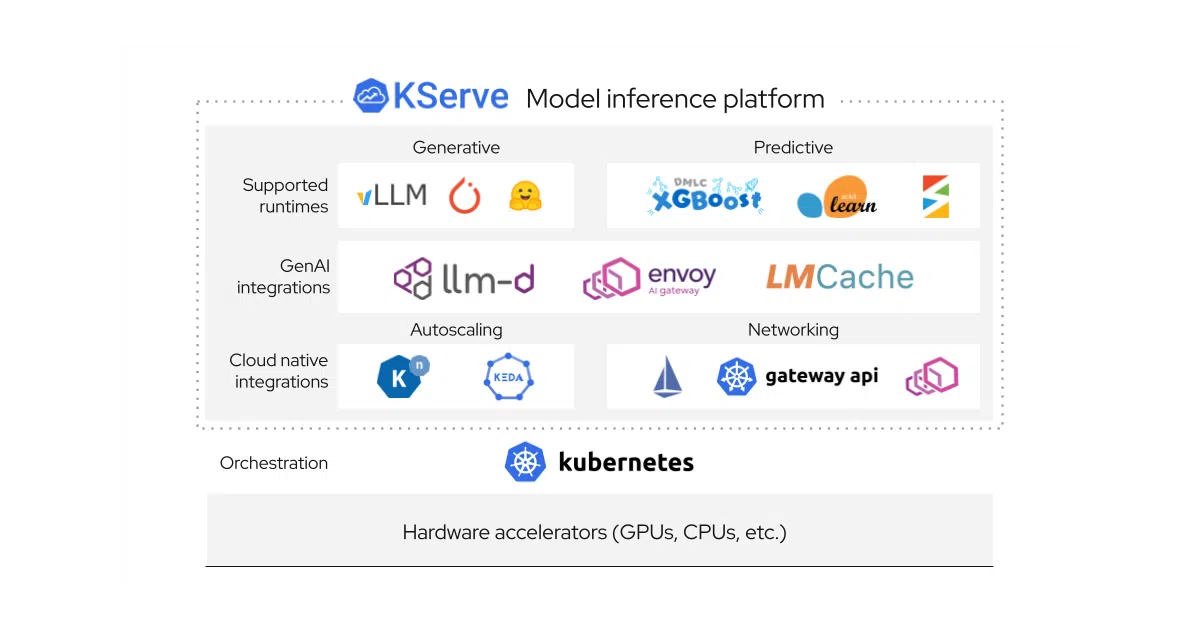
What it does
KServe is a Kubernetes-native inference platform that serves both generative AI (LLMs via vLLM, llm-d, Hugging Face) and traditional predictive models (TensorFlow, PyTorch, XGBoost, ONNX, etc.). It wraps the messy parts of model deployment — autoscaling, canary rollouts, request routing, GPU memory management, even scale-to-zero — into a single InferenceService CRD. The project is a CNCF incubating effort and ships as part of Kubeflow.
The interesting bit
Most serving tools pick a lane: LLM-optimized or classic ML-optimized. KServe’s bet is that enterprises need both and would rather not run two entirely separate platforms. It also standardizes on an OpenAI-compatible protocol for LLMs, which is a pragmatic concession to where the ecosystem has already landed.
Key highlights
- Native vLLM and llm-d backends with KV cache offloading to CPU/disk for longer sequences
- OpenAI-compatible inference protocol for LLM integration
- Scale-to-zero for predictive workloads; request-based autoscaling for both generative and predictive patterns
- Built-in model explainability, drift detection, outlier detection, and adversarial detection for predictive models
- Optional ModelMesh mode for high-density, frequently-changing model serving
- Three installation modes: raw Kubernetes (lightweight), Knative (serverless, default), or ModelMesh (high-scale)
Caveats
- The “lightweight” raw Kubernetes installation explicitly drops canary deployments and scale-to-zero — trade-offs are real
- The README is heavy on feature lists and light on architecture specifics; you’ll need to dig into the website docs for real design detail
Verdict
Worth evaluating if you’re already on Kubernetes and serving a mix of LLMs and traditional models. Probably overkill if you’re only running one model type or aren’t committed to K8s operational complexity.
Frequently asked
- What is kserve/kserve?
- KServe tries to stop your infrastructure from splintering every time a new AI framework appears.
- Is kserve open source?
- Yes — kserve/kserve is open source, released under the Apache-2.0 license.
- What language is kserve written in?
- kserve/kserve is primarily written in Go.
- How popular is kserve?
- kserve/kserve has 5.7k stars on GitHub.
- Where can I find kserve?
- kserve/kserve is on GitHub at https://github.com/kserve/kserve.