karpathy/autoresearch
Where you stop editing Python and start editing prompts
A minimal single-GPU framework that lets an AI agent run overnight LLM experiments while the human only edits a markdown brief.
Velocity · 7d
+83
★ / day
Trend
↘cooling
star history
What it does
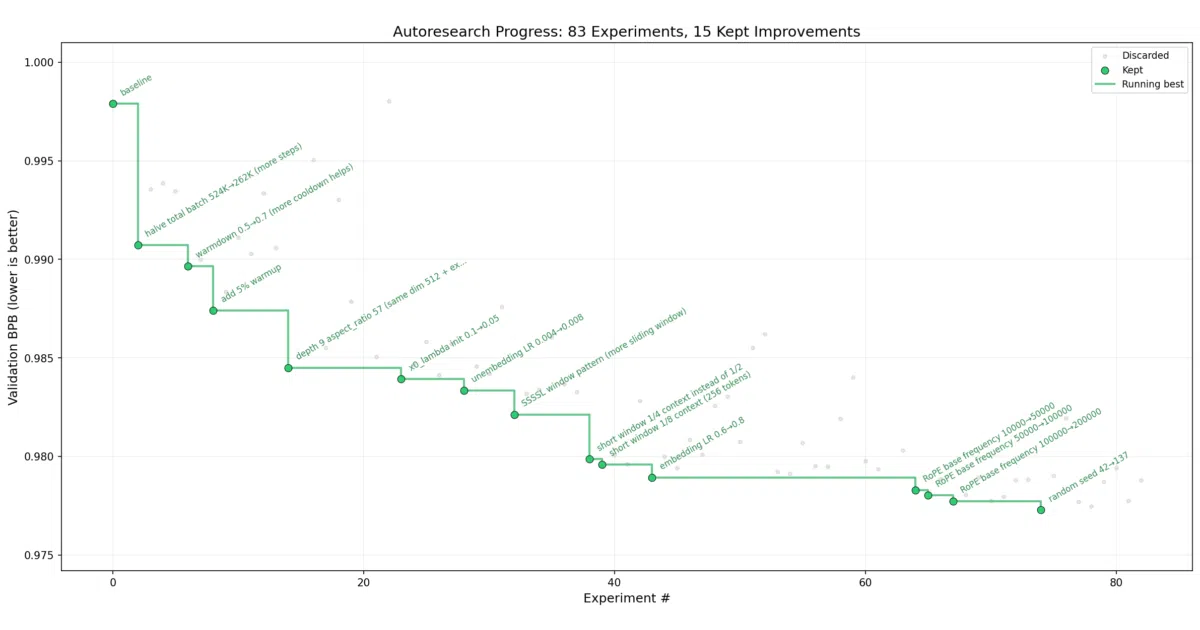
autoresearch gives a coding agent direct access to a stripped-down nanochat training loop on one GPU. The agent edits train.py—tweaking architecture, optimizers, or hyperparameters—then trains for a fixed five-minute wall-clock window and keeps changes only if validation bits per byte improves. The human’s entire job is to refine program.md, a markdown file that acts as the agent’s research brief, rather than touching Python directly. You wake up to a log of experiments and, ideally, a better model.
The interesting bit
The fixed five-minute wall-clock budget is the subtle glue: it makes every experiment directly comparable even if the agent swaps the optimizer or halves the model depth, because the score is always validation bits per byte under the same time constraint. By narrowing the agent’s scope to a single file and the human’s scope to a single markdown brief, the project turns overnight GPU cycles into a reproducible, diff-reviewable research log.
Key highlights
- Single-file agent scope: the agent only modifies
train.py, keeping diffs small and reviewable. - Human edits
program.md, a “super lightweight skill” that defines the research org, not Python code. - Fixed 5-minute runs produce roughly twelve experiments per hour, comparable on the same hardware regardless of architecture changes.
- Self-contained stack: PyTorch, a single NVIDIA GPU, no distributed training or external config systems.
- Metric is
val_bpb(validation bits per byte), chosen to be independent of vocabulary size so architectural edits are fairly judged.
Caveats
- Requires a single NVIDIA GPU; the author explicitly defers CPU, MPS, and AMD support to community forks to avoid code bloat.
- The default
program.mdis intentionally bare bones, so the quality of overnight results hinges on how much you iterate that brief. - Cross-machine comparison is broken by design: a faster GPU processes more tokens in the same five-minute window, so
val_bpbscores are hardware-bound.
Verdict
Grab this if you want to experiment with agent-driven optimization and have a spare NVIDIA GPU to burn cycles on overnight. Skip it if you are looking for a finished research platform or lack the hardware to run the default nanochat setup.
Frequently asked
- What is karpathy/autoresearch?
- A minimal single-GPU framework that lets an AI agent run overnight LLM experiments while the human only edits a markdown brief.
- Is autoresearch open source?
- Yes — karpathy/autoresearch is an open-source project tracked on heatdrop.
- What language is autoresearch written in?
- karpathy/autoresearch is primarily written in Python.
- How popular is autoresearch?
- karpathy/autoresearch has 91.8k stars on GitHub and is currently cooling off.
- Where can I find autoresearch?
- karpathy/autoresearch is on GitHub at https://github.com/karpathy/autoresearch.