karpathy/arxiv-sanity-lite
Your personal arXiv bouncer, trained on TF-IDF and $5/month
A dead-simple paper recommender that learns what you like from the abstracts you tag, then emails you daily so you stop drowning in preprints.
Not currently ranked — collecting fresh signals.
star history
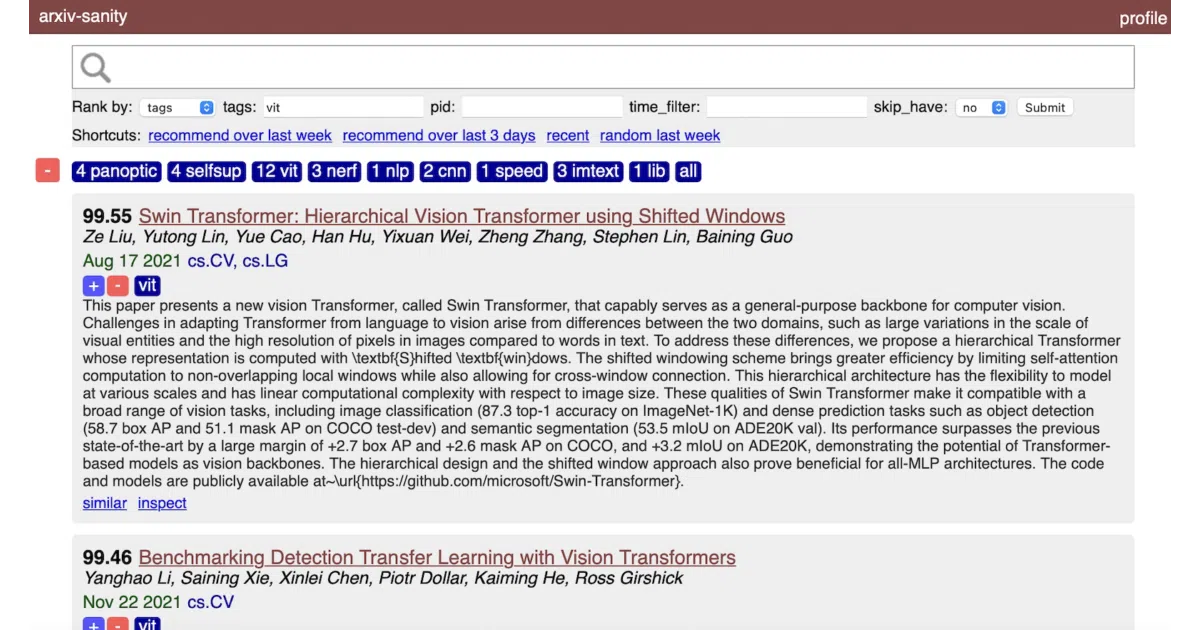
What it does
arxiv-sanity-lite polls the arXiv API, downloads paper metadata, and lets you tag whatever catches your eye. It then trains an SVM on TF-IDF vectors of paper abstracts per tag, and surfaces similar new papers in a Flask web UI. You can search, sort, and filter results; a daily cron job can email you fresh recommendations via SendGrid. The whole thing runs on a $5/month Linode Nanode indexing about 30K papers.
The interesting bit
The heavy lifting is classic ML — SVMs over TF-IDF, not embeddings or transformers — which makes the compute.py step cheap enough to skip when no new papers arrive. The “lite” in the name is honest: this is a from-scratch rewrite of the original arxiv-sanity, stripped to polling, tagging, and linear classification.
Key highlights
- Self-hosted, single-directory deployment (
data/holds everything) - Cron-friendly update pipeline:
arxiv_daemon.pyfetches,compute.pyfeaturizes,serve.pyhosts - Optional daily email digests via
send_emails.py+ SendGrid - Live demo running at arxiv-sanity-lite.com
- MIT licensed
Caveats
- Search iterates the full database; no reverse index yet
- The metadata store uses sqlitedict instead of proper SQLite tables
- Mobile UI needs media queries (per the author’s own todo list)
Verdict
Good fit if you want a hackable, low-cost paper filter and don’t need semantic search or LLM summaries. Skip it if you’re looking for state-of-the-art NLP or a polished mobile experience.
Frequently asked
- What is karpathy/arxiv-sanity-lite?
- A dead-simple paper recommender that learns what you like from the abstracts you tag, then emails you daily so you stop drowning in preprints.
- Is arxiv-sanity-lite open source?
- Yes — karpathy/arxiv-sanity-lite is open source, released under the MIT license.
- What language is arxiv-sanity-lite written in?
- karpathy/arxiv-sanity-lite is primarily written in Python.
- How popular is arxiv-sanity-lite?
- karpathy/arxiv-sanity-lite has 1.7k stars on GitHub.
- Where can I find arxiv-sanity-lite?
- karpathy/arxiv-sanity-lite is on GitHub at https://github.com/karpathy/arxiv-sanity-lite.