jonathan-laurent/AlphaZero.jl
AlphaZero in 2,000 lines: Julia beats Python at its own game
A readable, hackable implementation of DeepMind's algorithm that trains on a desktop GPU instead of a server farm.
Velocity · 7d
+0.5
★ / day
Trend
→steady
star history
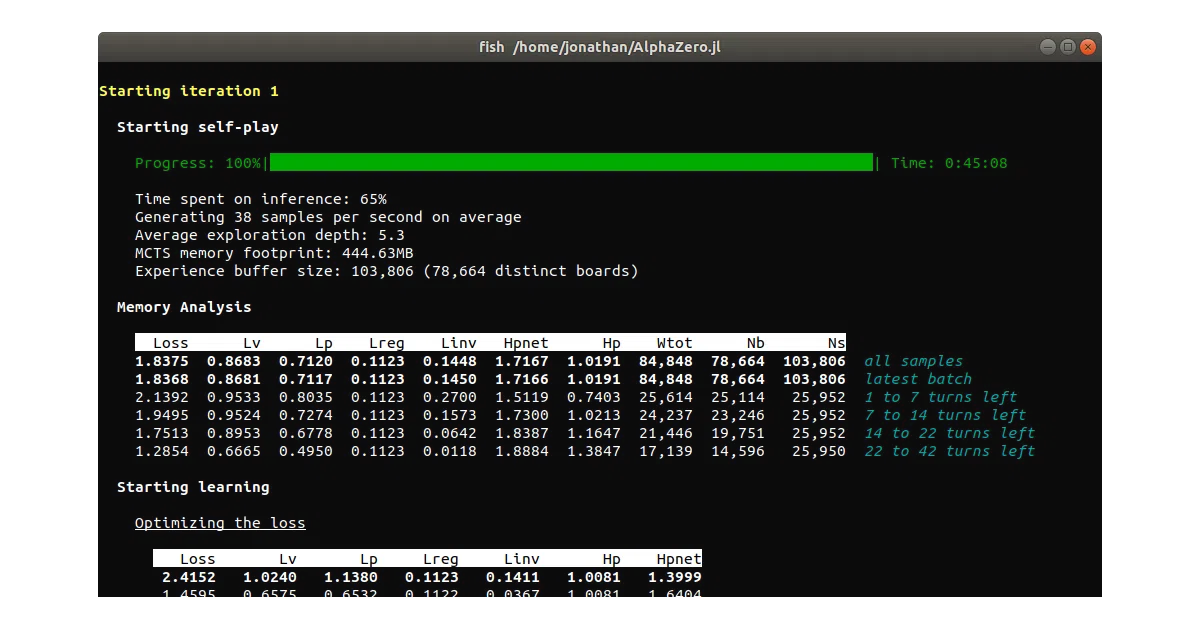
What it does AlphaZero.jl implements DeepMind’s AlphaZero algorithm for learning board games through self-play. The core logic fits in about 2,000 lines of Julia, with generic interfaces for adding new games or swapping neural network frameworks. It ships with a working Connect Four example that trains in roughly one hour per iteration on a mid-range desktop with an RTX 2070.
The interesting bit The project bets that Julia’s combination of high-level syntax and near-C performance can solve a problem usually reserved for C++ behemoths like Leela Zero. The README claims one to two orders of magnitude speedup over pure Python alternatives (JAX-based libraries excluded), and the same code runs distributed across a cluster without modification. That’s the kind of scaling story Python envies.
Key highlights
- Core algorithm: ~2,000 lines of “pure, hackable” Julia
- Generic interfaces for new games and learning frameworks
- Distributed training supported without code changes
- Includes interactive training UI and game explorer
- Connect Four agent learns from self-play with no prior knowledge or baseline exposure
- Network-only evaluation included: the raw neural network eventually outperforms a depth-5 minmax heuristic
Caveats
- The “one to two orders of magnitude” speed claim excludes JAX-based competitors, which narrows the comparison field significantly
- Requires a GPU for practical training times; CPU-only would likely be painful
- Occasional GR plotting bug needs a workaround environment variable (
GKSwstype=100)
Verdict Researchers and students who want to experiment with AlphaZero without wrestling with C++ or renting a cloud cluster should look here. Production engineers needing maximum throughput for small networks should consider the related AlphaGPU.jl instead.