jasonwei20/eda_nlp
Four cheap tricks that beat fancy language models (sometimes)
A 2019 EMNLP paper shows synonym-swapping and word deletion can outperform data-hungry augmentation methods on tiny text-classification datasets.
Not currently ranked — collecting fresh signals.
star history
What it does
EDA generates synthetic training sentences for text classification using four elementary operations: synonym replacement, random insertion, random swap, and random deletion. You feed it a tab-separated file of label\tsentence pairs; it spits out an augmented version with up to 16 synthetic variants per original sentence. The whole pipeline runs in under five minutes and needs only NLTK’s WordNet.
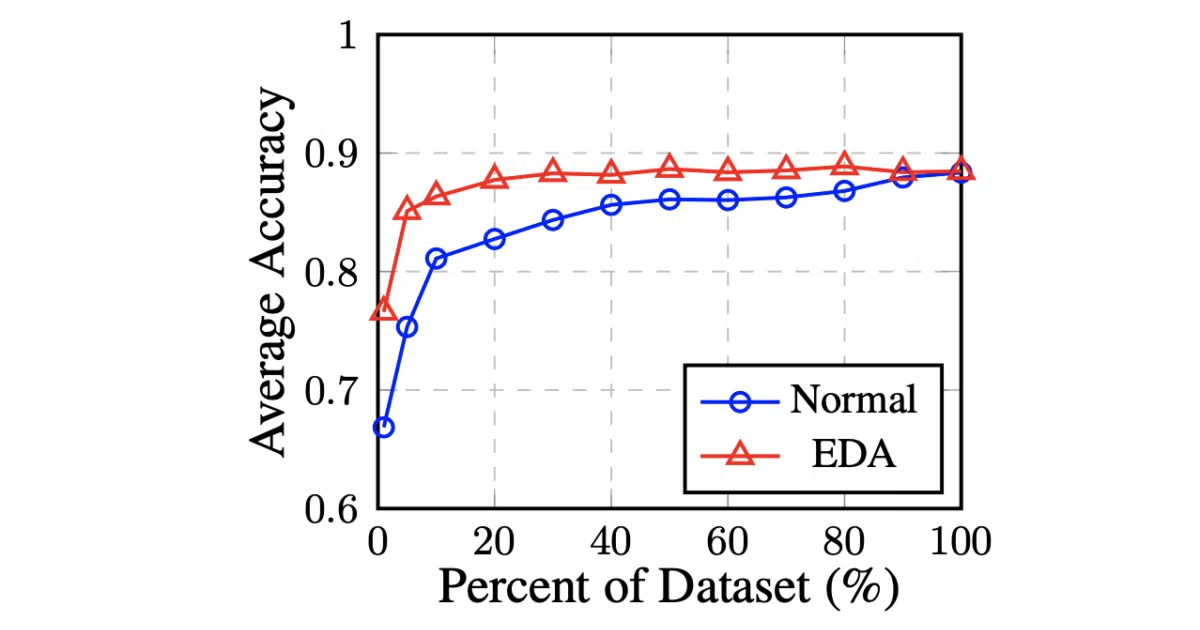
The interesting bit
The punchline is in the small-data regime. The authors found “substantial improvements on datasets of size N < 500” — the exact place where training a language model on external data just to augment your corpus is comically expensive. EDA’s value proposition is essentially: why rent a GPU cluster when a thesaurus and some dice will do?
Key highlights
- Four tunable operations (SR, RI, RS, RD) with per-technique alpha parameters
- Default generates 9 augmented sentences per original; configurable via
--num_aug - Requires only
pip install nltkand a WordNet download — no transformers, no CUDA - CLI interface:
python code/augment.py --input=your_file.txt - Chinese-language fork exists (external implementation)
Caveats
- The experiment code is explicitly noted as “not documented” and guidance is limited to a single GitHub issue
- Input format is rigid (
label\tsentencewith a tab separator) - The authors warn: “Do not email me with questions, as I will not reply”
Verdict Worth a shot if you’re scraping by with <500 labeled sentences and need a quick augmentation baseline. Skip it if you already have abundant data or need augmentation for generation/seq2seq tasks — this is classification-only territory.
Frequently asked
- What is jasonwei20/eda_nlp?
- A 2019 EMNLP paper shows synonym-swapping and word deletion can outperform data-hungry augmentation methods on tiny text-classification datasets.
- Is eda_nlp open source?
- Yes — jasonwei20/eda_nlp is an open-source project tracked on heatdrop.
- What language is eda_nlp written in?
- jasonwei20/eda_nlp is primarily written in Python.
- How popular is eda_nlp?
- jasonwei20/eda_nlp has 1.7k stars on GitHub.
- Where can I find eda_nlp?
- jasonwei20/eda_nlp is on GitHub at https://github.com/jasonwei20/eda_nlp.