intentee/paddler
A Load Balancer for LLMs That Fits in One Binary
Self-host large language and vision models at scale without the microservices headache.
Not currently ranked — collecting fresh signals.
star history
What it does
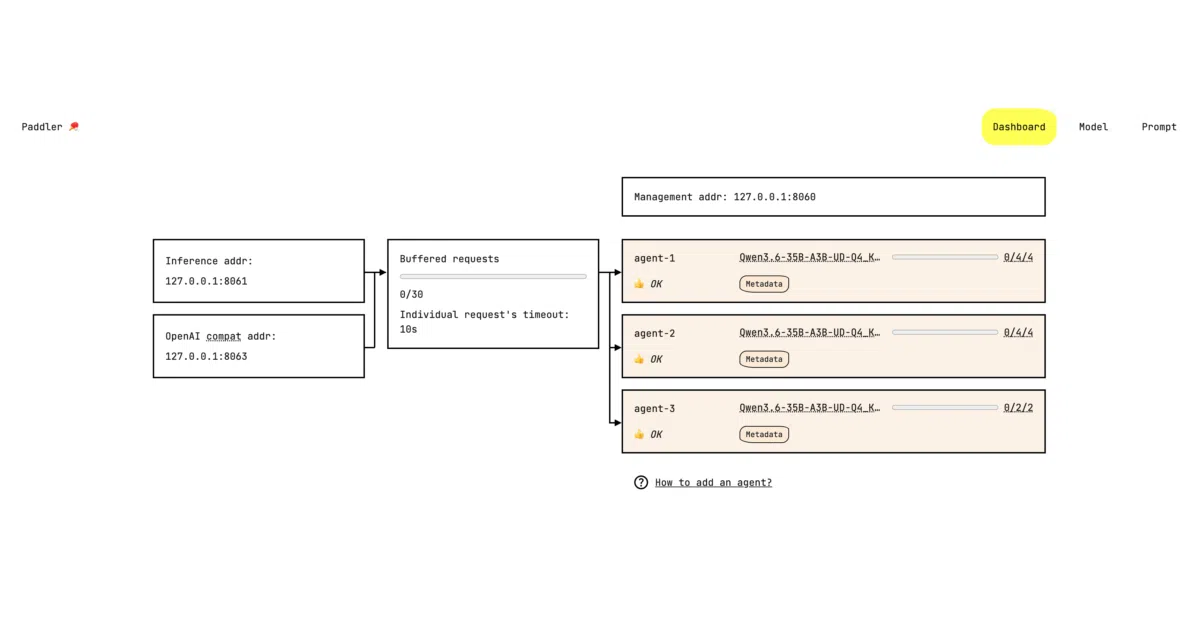
Paddler is an open-source load balancer and serving layer for self-hosted LLMs and VLMs. It wraps a built-in llama.cpp engine inside a single Rust binary divided into two roles: a balancer that routes requests and agents that handle inference through dedicated slots. It runs on CPU or GPU and targets teams who want to escape per-token cloud pricing.
The interesting bit The architecture is aggressively minimal. Agents register dynamically with the balancer, so you can wire them into autoscaling tools or let a coworker with a spare RTX 5090 join the cluster ad hoc. A built-in request buffer even lets the fleet scale to zero and back up without dropping traffic. If terminals make you wince, a beta desktop app can turn a pile of office laptops into a local AI cluster.
Key highlights
- Custom llama.cpp slot implementation with per-slot context and KV cache management
- Dynamic agent registration and request buffering for scale-to-zero workflows
- Built-in web admin panel for monitoring, model configuration, and prompt testing
- Desktop application (beta) for local multi-device clustering without command-line interaction
- Multimodal model support as of version 3.0
Caveats
- The desktop application is still in beta.
- Minimum Supported Rust Version is 1.88.0, which is aggressively recent for building from source.
Verdict DevOps and product teams that need data privacy, predictable costs, or compliance-friendly self-hosting should try this; shops already content with managed cloud APIs and heavy container orchestration can skip it.
Frequently asked
- What is intentee/paddler?
- Self-host large language and vision models at scale without the microservices headache.
- Is paddler open source?
- Yes — intentee/paddler is open source, released under the Apache-2.0 license.
- What language is paddler written in?
- intentee/paddler is primarily written in Rust.
- How popular is paddler?
- intentee/paddler has 1.6k stars on GitHub.
- Where can I find paddler?
- intentee/paddler is on GitHub at https://github.com/intentee/paddler.