ictnlp/LLaVA-Mini
Compressing 576 Vision Tokens Into One
It exists to compress every image into a single vision token, slashing FLOPs and VRAM without surrendering the visual understanding.
Not currently ranked — collecting fresh signals.
star history
What it does
LLaVA-Mini is a vision-language model built atop LLaVA and Llama 3.1 8B that handles images, high-resolution images, and video. Instead of passing hundreds of visual tokens to the language backbone for every frame, it dynamically compresses each image into exactly one vision token. The result is a unified model that answers questions about visual input while keeping compute and memory footprints unusually small.
The interesting bit
The authors used interpretability analysis to explore how LMMs actually use visual tokens, then built a compression scheme that weights important regions more heavily. Their finding is that you can get by with far fewer tokens than typically fed into the backbone—specifically, one.
Key highlights
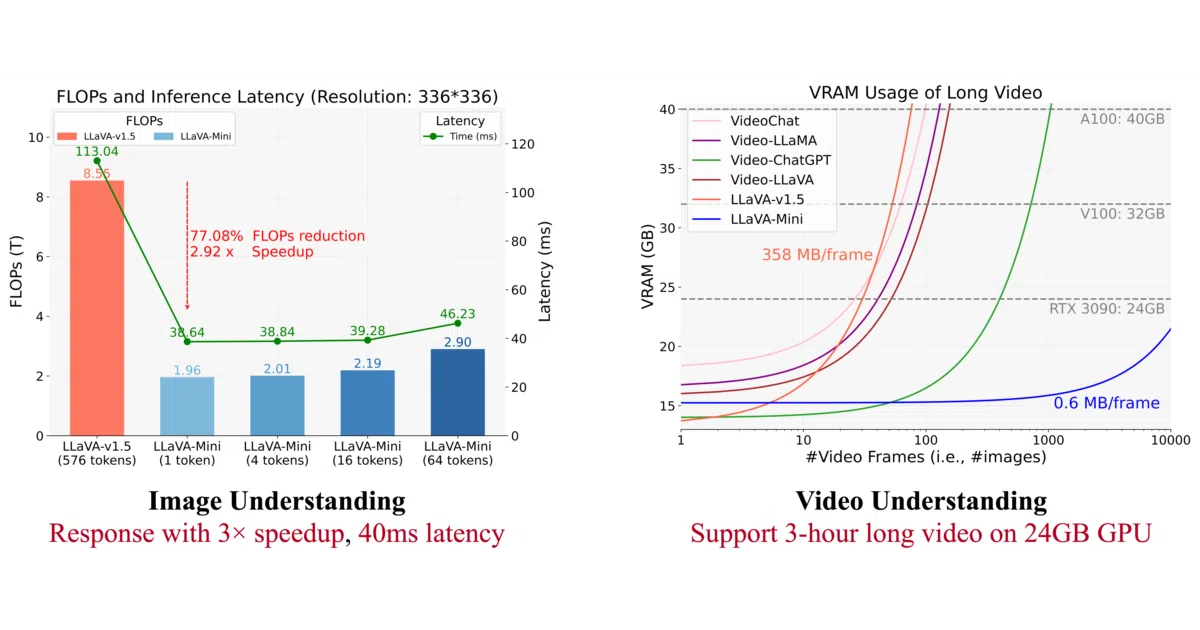
- Extreme compression: Reduces the standard 576 vision tokens per image to 1—a 0.17% compression rate—while claiming parity with LLaVA-v1.5 on understanding tasks.
- Dramatic speedups: Cuts FLOPs by 77%, drops per-image latency from 100 ms to 40 ms, and shrinks VRAM usage from 360 MB to 0.6 MB per image.
- Long-video capable: Can process over 10,000 frames on a 24 GB GPU, which the authors say supports 3-hour video understanding.
- Dynamic attention: The compression map highlights salient regions (brighter areas get heavier weighting), so the single token is not a naive average.
Verdict
Worth a look if you are bottlenecked by VRAM or latency when running vision-language models locally, especially on long videos. Skip it if you need provably state-of-the-art accuracy on every benchmark and would rather pay cloud API costs than trade a few points for efficiency.
Frequently asked
- What is ictnlp/LLaVA-Mini?
- It exists to compress every image into a single vision token, slashing FLOPs and VRAM without surrendering the visual understanding.
- Is LLaVA-Mini open source?
- Yes — ictnlp/LLaVA-Mini is open source, released under the Apache-2.0 license.
- What language is LLaVA-Mini written in?
- ictnlp/LLaVA-Mini is primarily written in Python.
- How popular is LLaVA-Mini?
- ictnlp/LLaVA-Mini has 575 stars on GitHub.
- Where can I find LLaVA-Mini?
- ictnlp/LLaVA-Mini is on GitHub at https://github.com/ictnlp/LLaVA-Mini.