howl-anderson/Chinese_models_for_SpaCy
The community model that shamed SpaCy into going native
A stopgap Chinese NLP model so capable that the official SpaCy team copied its homework.
Not currently ranked — collecting fresh signals.
star history
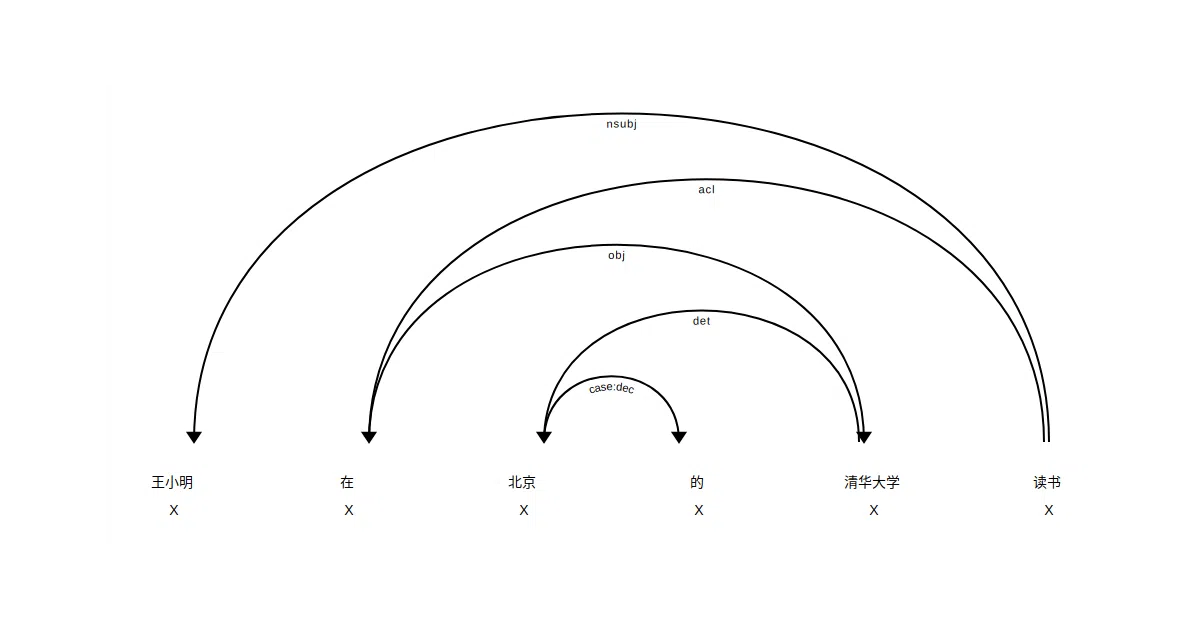
What it does
Trains SpaCy v2 models on Chinese text so you get tokenization, dependency parsing, and NER out of the box. It wraps the OntoNotes 5.0 corpus into SpaCy’s pipeline format, then adds a convenience alias (zh) so downstream tools like Rasa NLU can find it.
The interesting bit
The README’s opening line is unusually honest: SpaCy’s official Chinese model now exists, it “referenced this project” and shares the same features, so this repo’s mission is “complete.” That’s a graceful exit for what was essentially a hostage negotiation with an open-source ecosystem — build the missing piece, prove demand, then watch the maintainers absorb it.
Key highlights
- Ships binary model files; install via
pipthenspacy linkfor alias convenience - Includes Binder-hosted Jupyter demo for browser-based testing
- Trained on OntoNotes 5.0 (free for organizational users, LDC licensing hassle required)
- Provides accelerated download mirrors for China-based users
- Web demo in
test.pyserves dependency parse visualizations locally
Caveats
- Maintenance mode only: bug fixes, no new features; official SpaCy
zhmodels are the future - Several
Docattributes are broken or questionable for Chinese:pos_,is_stop,shape_,is_alpha, andvectorquality are all flagged in the TODO - Requires manual OntoNotes 5.0 procurement through LDC — no bundled data
Verdict
Use this if you’re pinned to an older SpaCy v2 setup or need the exact training pipeline documented in workflow.md. Otherwise, migrate to SpaCy’s official Chinese models and send a thank-you note to howl-anderson for making them exist.
Frequently asked
- What is howl-anderson/Chinese_models_for_SpaCy?
- A stopgap Chinese NLP model so capable that the official SpaCy team copied its homework.
- Is Chinese_models_for_SpaCy open source?
- Yes — howl-anderson/Chinese_models_for_SpaCy is open source, released under the MIT license.
- What language is Chinese_models_for_SpaCy written in?
- howl-anderson/Chinese_models_for_SpaCy is primarily written in Jupyter Notebook.
- How popular is Chinese_models_for_SpaCy?
- howl-anderson/Chinese_models_for_SpaCy has 673 stars on GitHub.
- Where can I find Chinese_models_for_SpaCy?
- howl-anderson/Chinese_models_for_SpaCy is on GitHub at https://github.com/howl-anderson/Chinese_models_for_SpaCy.