graphdeeplearning/graphtransformer
Self-attention, but make it topological
A research repo that adapts the Transformer to arbitrary graphs by replacing sinusoidal position encodings with Laplacian eigenvectors.
Not currently ranked — collecting fresh signals.
star history
What it does
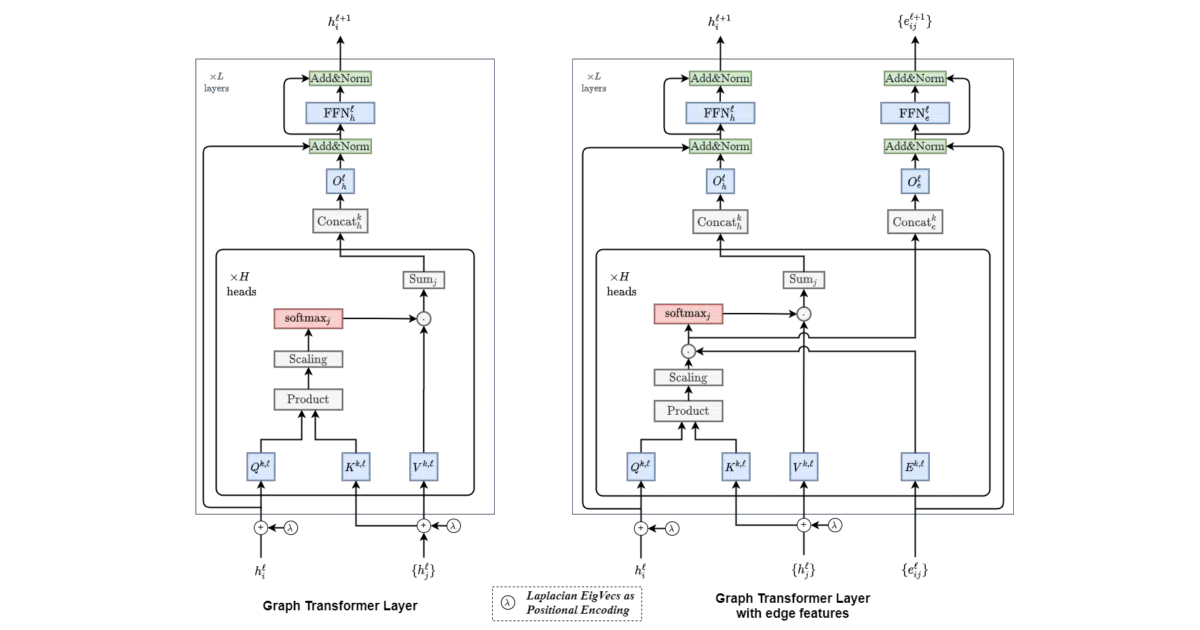
Implements the Graph Transformer from Dwivedi & Bresson’s AAAI'21 workshop paper. It takes the familiar multi-head self-attention mechanism and rewrites it for graph-structured data, where nodes have no natural sequence order and edges carry their own information.
The interesting bit
The position encoding is the elegant part. Instead of pretending a graph has a left-to-right reading order, it uses Laplacian eigenvectors — spectral properties of the graph itself — to tell the model where each node sits in the topology. The attention mechanism also operates over neighborhood connectivity rather than a full dense matrix, which keeps computation grounded in the actual graph structure.
Key highlights
- Attention is a function of neighborhood connectivity per node, not all-pairs
- Laplacian eigenvectors replace sinusoidal position encodings
- Layer normalization swapped for batch normalization
- Explicit edge representations for tasks like molecular bonds or knowledge graph relations
- Built on top of the benchmarking-gnns framework for reproducible comparisons
Caveats
- The repo is essentially a research artifact: installation, dataset download, and reproduction are manual multi-step processes
- No performance numbers or speed claims are stated in the README; you’ll need to run the benchmark or read the paper for empirical results
Verdict
Worth a look if you’re building graph neural networks and wondering whether Transformers can escape NLP’s sequence assumptions. Skip if you need a batteries-included library with pip-install convenience.
Frequently asked
- What is graphdeeplearning/graphtransformer?
- A research repo that adapts the Transformer to arbitrary graphs by replacing sinusoidal position encodings with Laplacian eigenvectors.
- Is graphtransformer open source?
- Yes — graphdeeplearning/graphtransformer is open source, released under the MIT license.
- What language is graphtransformer written in?
- graphdeeplearning/graphtransformer is primarily written in Python.
- How popular is graphtransformer?
- graphdeeplearning/graphtransformer has 1k stars on GitHub.
- Where can I find graphtransformer?
- graphdeeplearning/graphtransformer is on GitHub at https://github.com/graphdeeplearning/graphtransformer.