google/prettytensor
TensorFlow's forgotten fluent API, frozen in 2016
A Google-built chainable wrapper that let you write neural networks like jQuery pipelines—before Keras became the default.
Not currently ranked — collecting fresh signals.
star history
What it does
Pretty Tensor wraps TensorFlow tensors in chainable objects so you can build multi-layer networks with method chaining: pt.wrap(input).flatten().fully_connected(200).softmax(...). It handles shape inference, variable scoping, and offers shortcuts for common patterns like LSTMs, GRUs, and inception-style branching.
The interesting bit
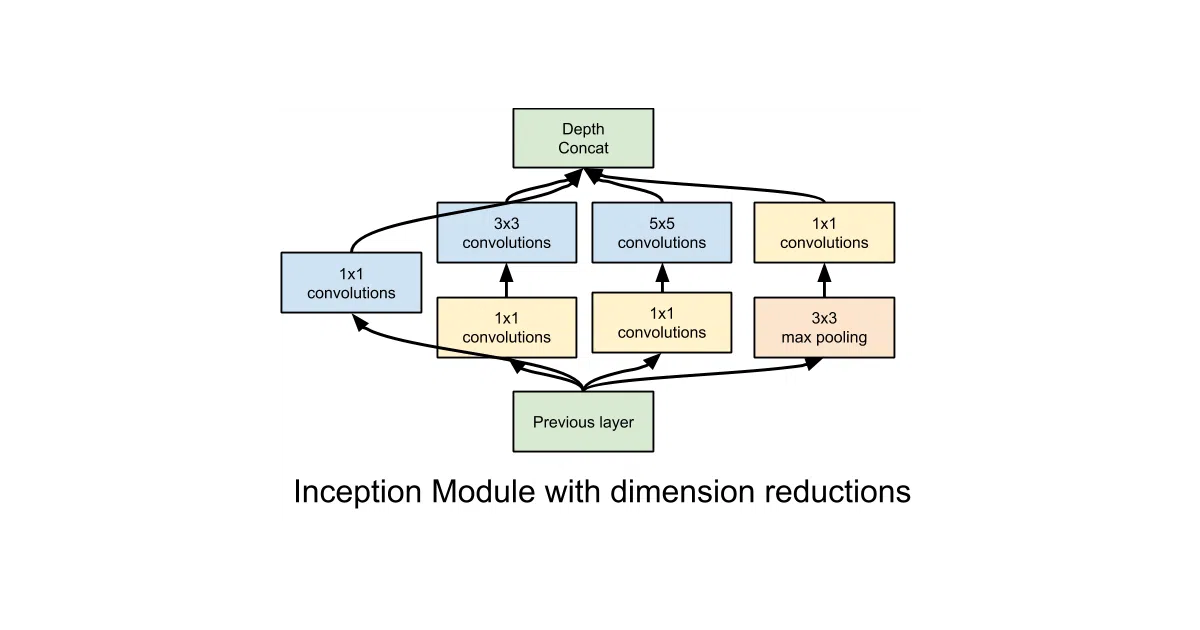
The “sequential” mode with subdivide() lets you write branching architectures—like inception modules—as nested context managers where code visually mirrors the graph structure. Templates with unbound variables provide a structured way to reuse parameters across recurrent unrolls, which was genuinely useful before TF’s native variable scopes matured.
Key highlights
- Chainable API:
pt.wrap(tensor).conv2d(...).fully_connected(...)with automatic shape handling defaults_scopefor setting shared parameters (activation functions, etc.) across layerssubdivide(n)for readable multi-branch architectures with automatic rejoining- Template system for guaranteed variable reuse in RNNs and other repeated structures
@Registerand@RegisterCompoundOpdecorators for extending the API with custom operations- Thin wrapper: wrapped tensors work almost anywhere native tensors do, and
apply()drops into raw TensorFlow functions
Caveats
- README explicitly notes: “Head is tested against the TensorFlow nightly builds”—stability was chasing a moving target even then
- Uses deprecated TensorFlow 1.x idioms (
tf.initialize_all_variables(),tf.Session(),tf.placeholder) with no evidence of 2.x migration - Python 2 print syntax in examples (
print 'Accuracy: %g') dates the project firmly to pre-2018
Verdict
A historical curiosity for researchers maintaining legacy TF 1.x codebases, or anyone studying API design evolution. Everyone else should use Keras or native PyTorch/TF 2.x. The 1,227 stars are mostly a time capsule.
Frequently asked
- What is google/prettytensor?
- A Google-built chainable wrapper that let you write neural networks like jQuery pipelines—before Keras became the default.
- Is prettytensor open source?
- Yes — google/prettytensor is an open-source project tracked on heatdrop.
- What language is prettytensor written in?
- google/prettytensor is primarily written in Python.
- How popular is prettytensor?
- google/prettytensor has 1.2k stars on GitHub.
- Where can I find prettytensor?
- google/prettytensor is on GitHub at https://github.com/google/prettytensor.