google-research-datasets/wit
Wikipedia's image captions, mined into 37M training pairs
A Google Research dataset that turns Wikipedia's multilingual pages into pretraining fuel for vision-language models.
Not currently ranked — collecting fresh signals.
star history
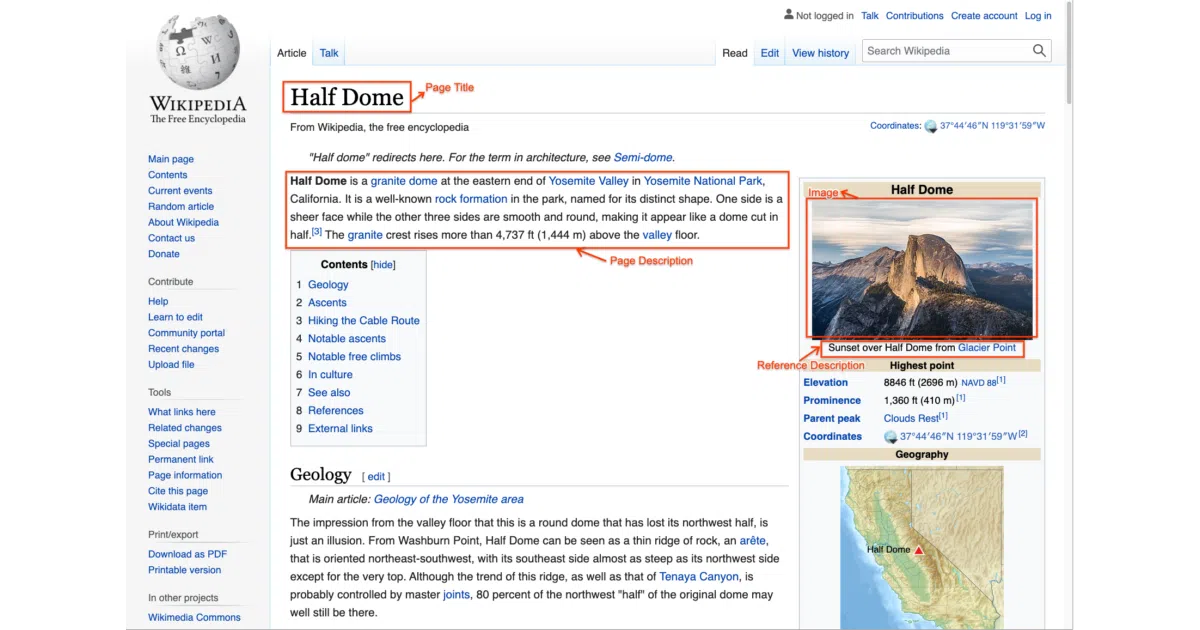
What it does WIT extracts image-text pairs from Wikipedia articles across 108 languages, yielding 37.6 million examples built from 11.5 million unique images. Each entry carries multiple text types—reference text, attribution, alt text, and surrounding context—rather than a single caption.
The interesting bit The dataset treats images as a “language-agnostic medium” to bootstrap multilingual understanding. Where most vision-language datasets are English-dominant, WIT has 100K+ pairs in 53 languages and 12K+ in all 108. It also includes page-level metadata and contextual information, which the authors note is a first for image-text datasets.
Key highlights
- 37.13M train / 261.8K val / 210.7K test splits, with 119.8M context texts in the mix
- Derived from Wikimedia content under CC BY-SA 3.0
- Won the Wikimedia Foundation Research Award of the Year in 2022
- Spawned follow-up work: WikiWeb2M (page-level multimodal), AToMiC, and a Kaggle competition
- Used by MURAL, a multimodal multitask retrieval model (EMNLP 2021)
Caveats
- The “largest publicly available” claim dates to 2021; larger datasets have likely emerged since
- Raw pixels and ResNet-50 embeddings are available through Wikimedia collaborators, not directly in this repo
- The repo itself is documentation and download pointers—no loading code provided
Verdict Grab this if you’re training or benchmarking multilingual vision-language models and need breadth over polish. Skip if you want a tight, English-only dataset with clean object-level annotations.
Frequently asked
- What is google-research-datasets/wit?
- A Google Research dataset that turns Wikipedia's multilingual pages into pretraining fuel for vision-language models.
- Is wit open source?
- Yes — google-research-datasets/wit is an open-source project tracked on heatdrop.
- How popular is wit?
- google-research-datasets/wit has 1.1k stars on GitHub.
- Where can I find wit?
- google-research-datasets/wit is on GitHub at https://github.com/google-research-datasets/wit.