fundamentalvision/BEVFormer
Camera-only 3D perception that nearly matches LiDAR
BEVFormer exists to make expensive LiDAR optional by teaching surround cameras to build bird's-eye-view scenes through spatiotemporal attention.
Not currently ranked — collecting fresh signals.
star history
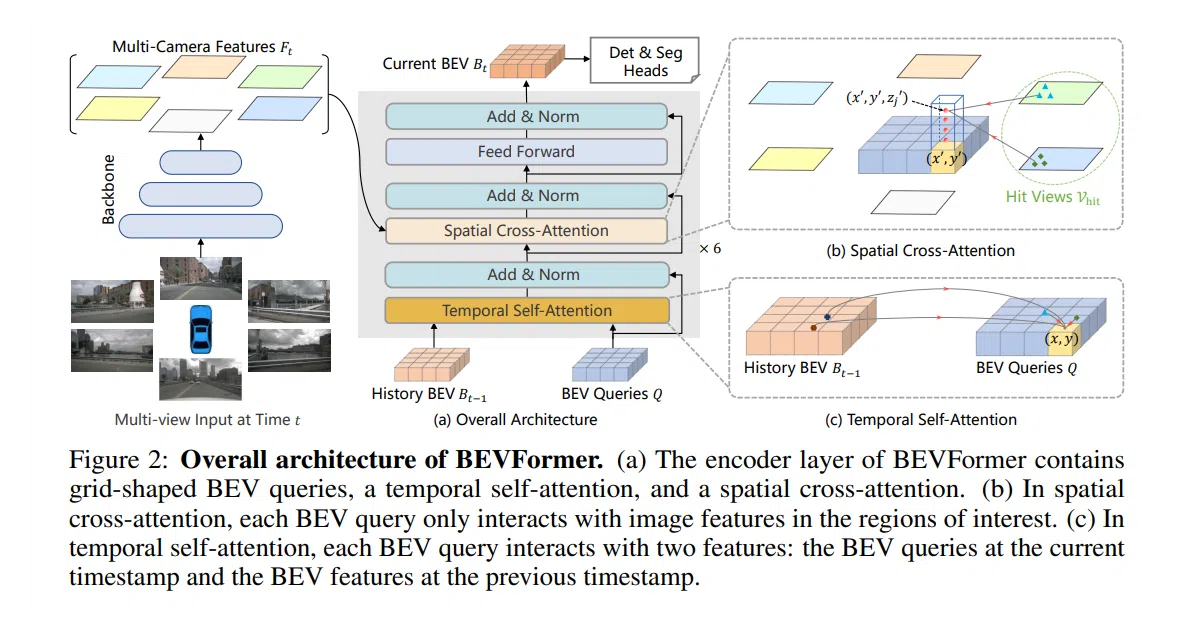
What it does BEVFormer is an autonomous driving perception framework that performs 3D object detection and semantic map segmentation using only camera input. It processes multi-camera video streams into unified bird’s-eye-view (BEV) representations via transformer-based attention. The project targets performance parity with LiDAR-based systems while eliminating the need for LiDAR hardware.
The interesting bit The model uses predefined grid-shaped BEV queries that attend across both space and time. Spatial cross-attention lets each query extract features from relevant regions across all camera views, while temporal self-attention fuses historical BEV frames to maintain continuity. On the nuScenes test set, it achieved 56.9% NDS camera-only—nine points above prior camera-only work and roughly equivalent to LiDAR baselines.
Key highlights
- Official ECCV 2022 implementation with a full model zoo spanning tiny to base variants, plus BEVFormerV2 releases
- GPU memory requirements are substantial: the base config needs 28,500 MB, and V2 variants scale up to roughly 40 GB
- The team reports that a successor, BEVFormer++, ranked first in the Waymo Open Dataset 3D Camera-Only Detection Challenge
- BEV segmentation checkpoints and code remain unreleased according to the repository catalog
- Built atop open-source projects including
mmdetection3danddetr3d
Caveats
- BEV segmentation code and checkpoints are still marked as unreleased in the project catalog
- Training demands significant GPU memory even for smaller variants (6.5 GB+ for the tiny config)
Verdict Worth studying if you are researching camera-only 3D perception or BEV representation learning. Skip it if you need a lightweight, production-ready deployment or if you require the unreleased BEV segmentation components.
Frequently asked
- What is fundamentalvision/BEVFormer?
- BEVFormer exists to make expensive LiDAR optional by teaching surround cameras to build bird's-eye-view scenes through spatiotemporal attention.
- Is BEVFormer open source?
- Yes — fundamentalvision/BEVFormer is open source, released under the Apache-2.0 license.
- What language is BEVFormer written in?
- fundamentalvision/BEVFormer is primarily written in Python.
- How popular is BEVFormer?
- fundamentalvision/BEVFormer has 4.5k stars on GitHub.
- Where can I find BEVFormer?
- fundamentalvision/BEVFormer is on GitHub at https://github.com/fundamentalvision/BEVFormer.