fudan-zvg/SETR
Pure-transformer segmentation, circa 2021
SETR treats semantic segmentation as a sequence-to-sequence translation problem, using transformers to replace the usual CNN backbone for dense pixel prediction.
Not currently ranked — collecting fresh signals.
star history
What it does
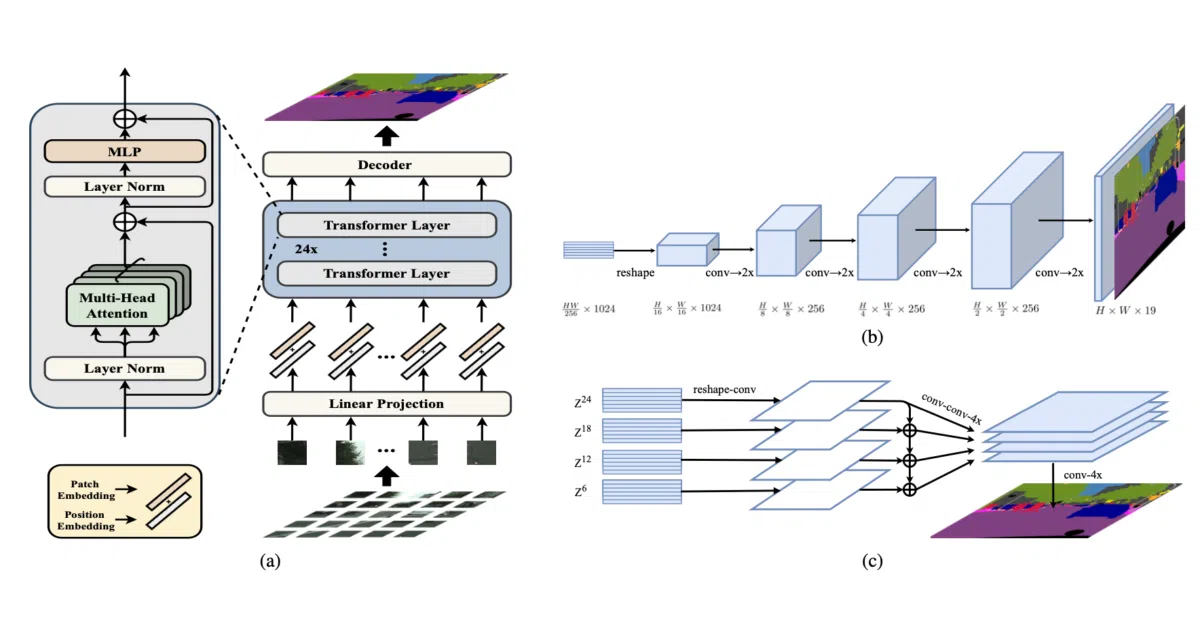
SETR approaches semantic segmentation as a sequence-to-sequence problem using transformers, taking the paper title literally. It provides three decoder variants—SETR-Naive, SETR-MLA, and SETR-PUP—and benchmarks them on Cityscapes, ADE20K, and Pascal Context. The repository has since absorbed HLG, a later hierarchical transformer family that adds ImageNet classification and COCO detection experiments alongside updated segmentation tables.
The interesting bit
This was CVPR 2021 work, early in the wave of applying transformers to dense prediction. The README now functions like a cumulative lab notebook, stacking HLG classification and detection tables atop the original segmentation benchmarks with almost no narrative glue.
Key highlights
- Sequence-to-sequence transformer formulation for pixel-level segmentation
- Three decoder heads:
SETR-Naive,SETR-MLA, andSETR-PUP - Cityscapes validation mIoU up to 79.34 for original SETR, and up to 82.9 for the later
SETR-HLG-Large - HLG ImageNet-1K classification reaches 84.1% Top-1 (
HLG-Largeat 224×224) - Pre-trained weights and config files provided for most variants
Caveats
- README is essentially a benchmark spreadsheet; architectural details are left to the papers
- Several Google Drive links for DeiT pre-trained weights are empty
- HLG detection section on COCO is truncated mid-table
Verdict
Researchers reproducing early transformer segmentation baselines or comparing against historical SOTA will find the weights and configs useful. Developers looking for a guided, well-documented training framework will likely bounce off the sparse README.
Frequently asked
- What is fudan-zvg/SETR?
- SETR treats semantic segmentation as a sequence-to-sequence translation problem, using transformers to replace the usual CNN backbone for dense pixel prediction.
- Is SETR open source?
- Yes — fudan-zvg/SETR is open source, released under the MIT license.
- What language is SETR written in?
- fudan-zvg/SETR is primarily written in Python.
- How popular is SETR?
- fudan-zvg/SETR has 1.1k stars on GitHub.
- Where can I find SETR?
- fudan-zvg/SETR is on GitHub at https://github.com/fudan-zvg/SETR.