fpgaminer/joycaption
A captioning model built to describe the internet, warts and all
JoyCaption is an open image captioning model built from scratch to generate training data for diffusion models, explicitly covering NSFW and niche art styles that commercial APIs censor or mangle.
Not currently ranked — collecting fresh signals.
star history
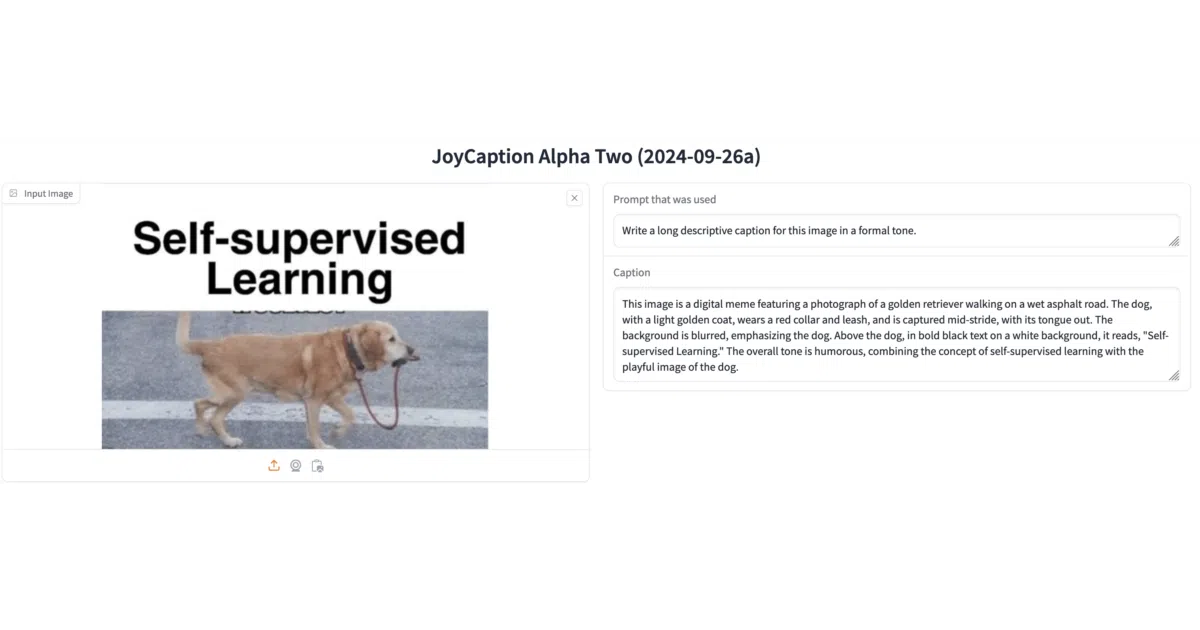
What it does
JoyCaption is a Visual Language Model that writes descriptive captions for images. It is designed specifically to feed diffusion model training pipelines, replacing expensive or censored APIs like ChatGPT. The model runs locally and can output everything from formal prose to Danbooru tag lists.
The interesting bit
The project openly targets the “uncensored” gap: it promises equal coverage of SFW and NSFW concepts without the absurd euphemisms (“cylindrical shaped object…”) typical of filtered models. It also explicitly trains on diverse styles—photoreal, anime, furry, digital art—rather than pretending the internet is only stock photography.
Key highlights
- Open weights with training scripts and detailed build logs promised, à la the bigASP project.
- Multiple caption personalities: descriptive, straightforward, Stable Diffusion prompt, MidJourney prompt, Danbooru tags, and e621 tags.
- Aims to match GPT4o caption quality while remaining free and unrestricted.
- Native
bfloat16requires roughly 17 GB of VRAM (comfortable on 24 GB GPUs); 8-bit and 4-bit quantization are supported.
Caveats
- Several output modes remain rough: casual tone sounds like “a robot pretending to be ‘hip,’” Stable Diffusion prompts glitch roughly 3% of the time, and MidJourney mode occasionally loops into repetition.
- Tag modes (Danbooru and e621) deliver lower accuracy than the main captioning styles.
- HuggingFace’s chat template handling for Llava models is “very fragile,” and misconfiguration can silently inject extra
<bos>tokens that degrade performance.
Verdict
Diffusion model trainers and dataset curators who need broad, unfiltered coverage should look here. If you just need generic SFW captions for a consumer app, the hardware requirements and rough edges are probably overkill.
Frequently asked
- What is fpgaminer/joycaption?
- JoyCaption is an open image captioning model built from scratch to generate training data for diffusion models, explicitly covering NSFW and niche art styles that commercial APIs censor or mangle.
- Is joycaption open source?
- Yes — fpgaminer/joycaption is open source, released under the Apache-2.0 license.
- What language is joycaption written in?
- fpgaminer/joycaption is primarily written in Jupyter Notebook.
- How popular is joycaption?
- fpgaminer/joycaption has 1.2k stars on GitHub.
- Where can I find joycaption?
- fpgaminer/joycaption is on GitHub at https://github.com/fpgaminer/joycaption.