facebookresearch/svoice
Speaker Separation That Handles the Full Dinner Table
SVoice separates an unknown number of overlapping speakers from a single audio recording using gated neural networks, scaling past the two-speaker ceiling where most methods collapse.
Not currently ranked — collecting fresh signals.
star history
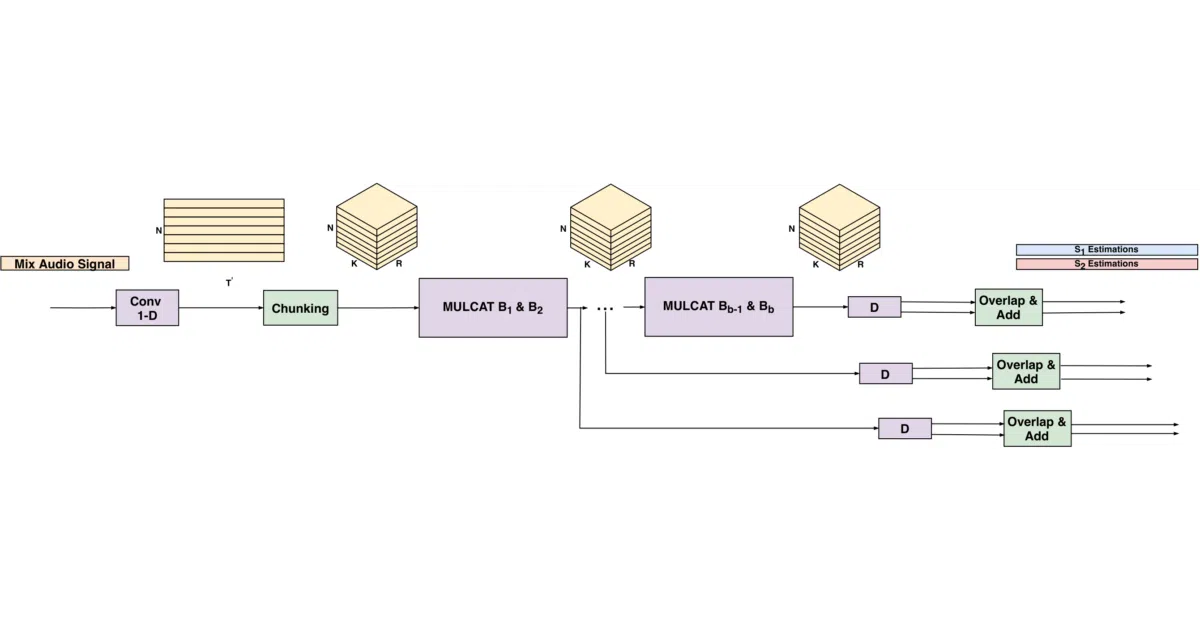
What it does SVoice takes a single audio recording of multiple people talking over each other and teases out the individual voices. Implemented in PyTorch, it uses gated neural networks to iteratively separate speakers while locking each voice to a fixed output channel. The system is built for the realistic case where you do not know the speaker count in advance.
The interesting bit Rather than guessing the number of speakers up front, the authors train a dedicated model for each cardinality and let the largest model vote on the actual headcount. It is a labor-intensive way to solve the unknown-source problem, but the payoff is real: the 7.5M-parameter network outperforms ConvTasNet and DPRNN on the reported SI-SNRi metrics, and it keeps separating intelligibly even when five people are talking at once.
Key highlights
- Reported SI-SNRi improvements range from 20.1 dB on two-speaker mixtures down to 10.6 dB on five-speaker chaos.
- Includes a synthetic data generator for noisy, reverberant rooms using the Allen and Berkley image method from 1979.
- Uses Hydra for hierarchical configuration and automatically resumes from checkpoints based on command-line overrides.
- At 7.5M parameters, it is lighter than several competing architectures while posting higher separation scores on the benchmark table.
Caveats
- The public code omits the
IDlossterm used in the paper, so exact reproduction of the published results is not guaranteed. - The documentation focuses heavily on training pipelines; it is unclear whether pre-trained checkpoints are provided or if you are expected to train from scratch.
Verdict A solid starting point for researchers working on multi-speaker source separation or anyone tired of two-speaker ceilings. If you are looking for a polished, ready-to-deploy speech separation API, this is still research-grade scaffolding.
Frequently asked
- What is facebookresearch/svoice?
- SVoice separates an unknown number of overlapping speakers from a single audio recording using gated neural networks, scaling past the two-speaker ceiling where most methods collapse.
- Is svoice open source?
- Yes — facebookresearch/svoice is an open-source project tracked on heatdrop.
- What language is svoice written in?
- facebookresearch/svoice is primarily written in Python.
- How popular is svoice?
- facebookresearch/svoice has 1.3k stars on GitHub.
- Where can I find svoice?
- facebookresearch/svoice is on GitHub at https://github.com/facebookresearch/svoice.