facebookresearch/map-anything
One transformer, twelve 3D tasks, zero patience required
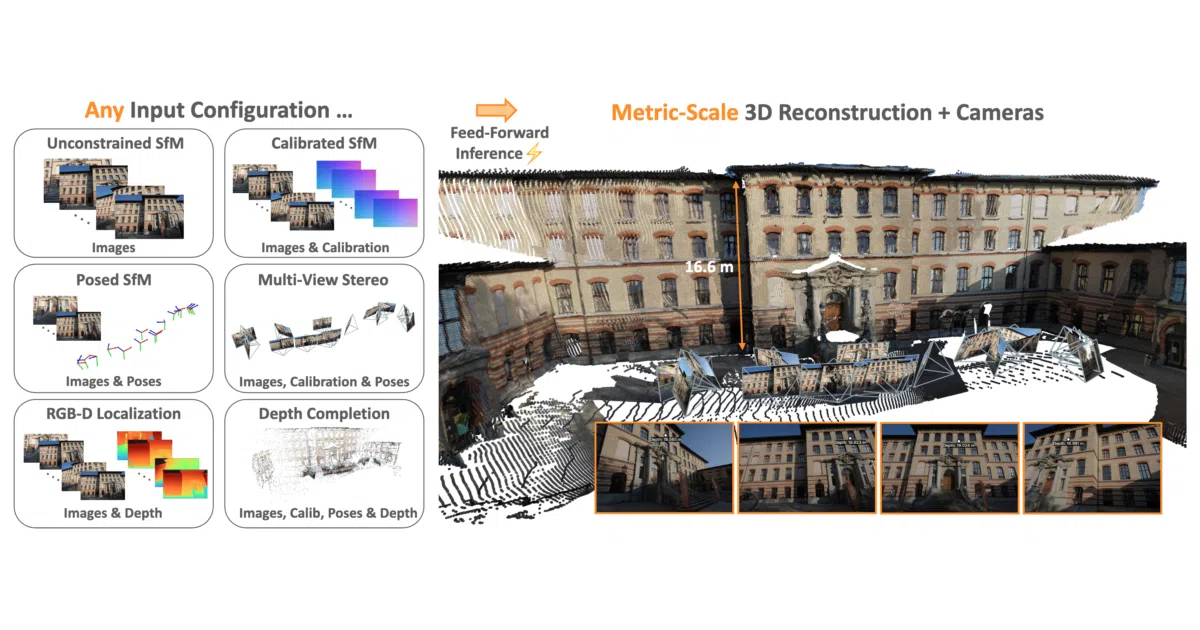
MapAnything turns a grab bag of inputs—images, poses, depth, calibration—into metric 3D geometry with a single feed-forward pass.
Not currently ranked — collecting fresh signals.
star history
What it does MapAnything is a research framework from Meta and CMU that trains one transformer end-to-end to regress metric 3D scene geometry. Feed it images alone, or mix in intrinsics, depth maps, or camera poses; it returns point clouds, depths, camera poses, and confidence masks in one shot. The framework wraps the full pipeline—data processing, training, inference, benchmarking, and profiling—in a modular Python package.
The interesting bit The “universal” claim is backed by a unified interface that can swap in other reconstruction models (VGGT, DUSt3R, MASt3R, Pi3-X, etc.) without rewriting your pipeline. It also exports directly to COLMAP and Gaussian Splatting, which saves the usual ritual of format conversion.
Key highlights
- Single model handles 12+ tasks: SfM, MVS, monocular depth, depth completion, registration, and others
- Memory-efficient inference mode claims up to 2,000 views on 140 GB VRAM with “negligible” speed trade-off (see their profiling section)
- Supports mixed inputs across views: one image might have only RGB, another RGB+depth+pose
- Apache 2.0 licensed model variant available on Hugging Face alongside the default release
- Built-in benchmarking and profiling tools to compare against external models
Caveats
- Camera poses must use the OpenCV cam2world convention; the README mentions a conversion helper but marks it TODO
- PyTorch and CUDA versions are unpinned, so environment setup is left to you
- The “negligible” speed/memory trade-off claim is theirs; verify against your own hardware
Verdict Worth a look if you’re building 3D reconstruction pipelines and want one model that handles messy, heterogeneous inputs without hand-tuning per-task pipelines. Skip it if you need guaranteed production robustness—this is explicitly framed as research code.
Frequently asked
- What is facebookresearch/map-anything?
- MapAnything turns a grab bag of inputs—images, poses, depth, calibration—into metric 3D geometry with a single feed-forward pass.
- Is map-anything open source?
- Yes — facebookresearch/map-anything is open source, released under the Apache-2.0 license.
- What language is map-anything written in?
- facebookresearch/map-anything is primarily written in Python.
- How popular is map-anything?
- facebookresearch/map-anything has 3.6k stars on GitHub.
- Where can I find map-anything?
- facebookresearch/map-anything is on GitHub at https://github.com/facebookresearch/map-anything.