facebookresearch/jepa
Meta's video model learns by guessing what happens next—in latent space
A self-supervised architecture that predicts features, not pixels, from unlabeled video.
Not currently ranked — collecting fresh signals.
star history
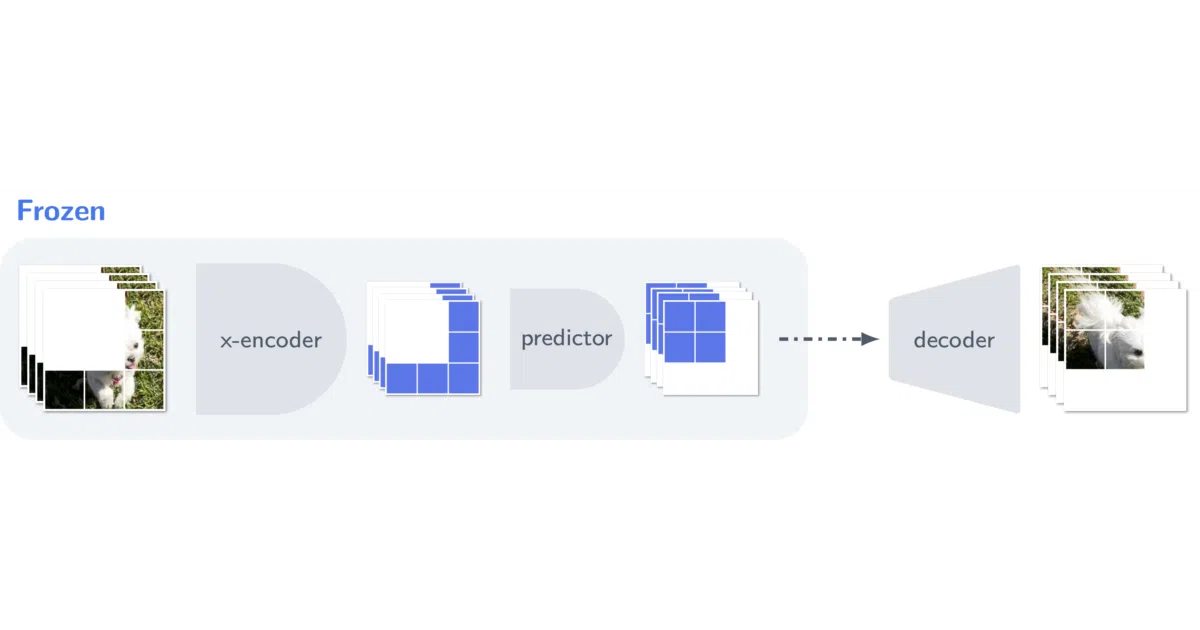
What it does V-JEPA trains vision transformers on raw video without labels, text, or pretrained encoders. The model watches unlabeled footage and learns visual representations by predicting masked features in a joint-embedding space rather than reconstructing pixels. Once trained, the backbone stays frozen; only a lightweight “attentive probe” gets fine-tuned for downstream tasks like Kinetics-400 or ImageNet classification.
The interesting bit Most generative video models decode to pixels, which is expensive and often unnecessary. V-JEPA predicts in latent space, then uses a separately trained diffusion decoder solely for visualization—like having a translator render your thoughts into images after you’ve already done the thinking. The README claims these feature predictions are “grounded” and spatio-temporally consistent with unmasked regions.
Key highlights
- Trains purely on an unsupervised feature-prediction objective—no negative examples, no human annotations, no pixel reconstruction loss
- Released checkpoints include ViT-L and ViT-H models trained on VideoMix2M at 224×224 and 384×384 resolutions
- Evaluation probes provided for K400 (82.0% top-1 with ViT-H/16), SSv2, ImageNet-1K (77.4%), Places205, and iNat21
- Code enforces strict separation: training loops live in
app/, evaluations inevals/, configs only inconfigs/ - Supports both Slurm clusters and local debugging with separate entrypoints
Caveats
- The README trails off mid-sentence during data preparation instructions, suggesting documentation remains incomplete
- All experiment parameters require hand-editing YAML config files rather than command-line flags
- Pretraining at the reported scale (batch size 3072) implies significant compute requirements
Verdict Worth studying if you’re building self-supervised video representations or exploring LeCun’s joint-embedding predictive architecture roadmap. Skip if you need a plug-and-play video generator—this is representation learning with a research codebase, not a product.
Frequently asked
- What is facebookresearch/jepa?
- A self-supervised architecture that predicts features, not pixels, from unlabeled video.
- Is jepa open source?
- Yes — facebookresearch/jepa is an open-source project tracked on heatdrop.
- What language is jepa written in?
- facebookresearch/jepa is primarily written in Python.
- How popular is jepa?
- facebookresearch/jepa has 4k stars on GitHub.
- Where can I find jepa?
- facebookresearch/jepa is on GitHub at https://github.com/facebookresearch/jepa.