duoan/TorchCode
Interview prep that makes you write softmax cold
A notebook-based judge that auto-grades your from-scratch PyTorch implementations, because whiteboard interviews demand muscle memory, not paper reading.
Velocity · 7d
+3.1
★ / day
Trend
↘cooling
star history
What it does
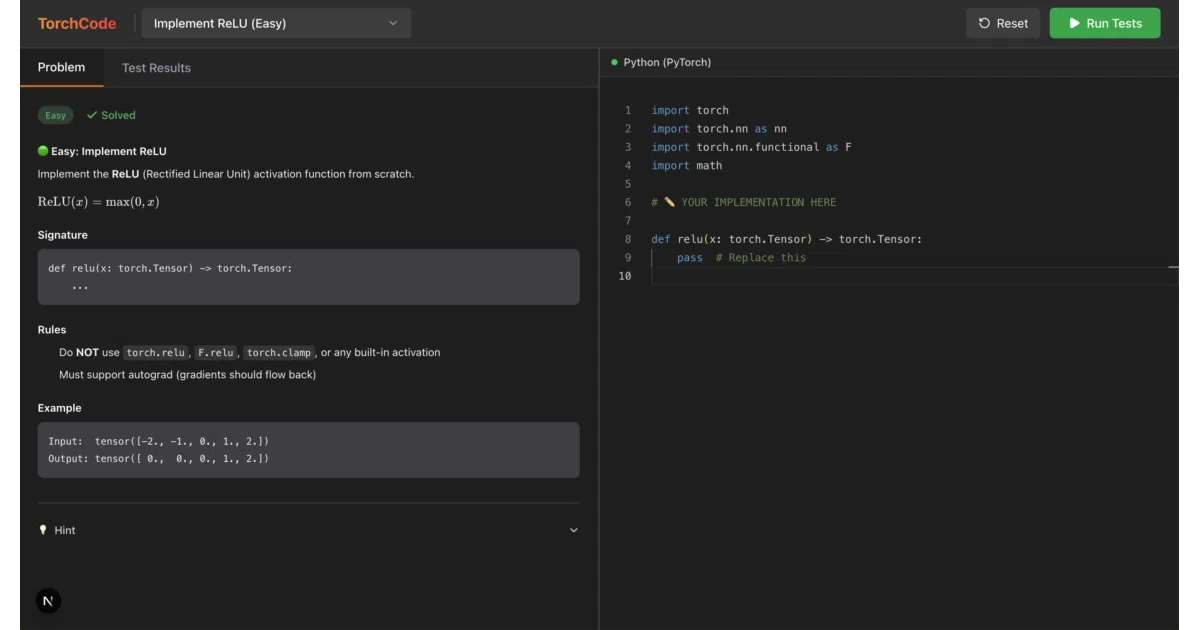
TorchCode is a collection of 40 Jupyter notebooks that ask you to rebuild core ML operations—ReLU, softmax, LayerNorm, multi-head attention, even full Transformer blocks—without reaching for torch.nn. An automated judge checks your output, gradients, and execution time, then colors each test case pass or fail like a competitive programming platform. You can run it inside Docker, on Hugging Face Spaces, or directly in Google Colab.
The interesting bit
The project treats tensor manipulation as a learnable skill rather than a library call, which is exactly what the README claims top labs (Meta, DeepMind, OpenAI) test for. The judge doesn’t just check numerical correctness; it verifies gradients and timing, so you know your implementation is both right and reasonably efficient.
Key highlights
- 40 curated problems ranked by real interview frequency, from foundational activations up to full Transformer blocks
- Judge checks numerical correctness, gradients, and timing with colored pass/fail feedback
- Hints and reference solutions available when you’re stuck, so you can learn the pattern without memorizing a spoiler
- One-click reset per notebook for deliberate repetition of the same problem
- Standalone Next.js + FastAPI IDE option alongside the primary Jupyter flow
Caveats
- The pre-built Docker image is noted as potentially unavailable on Apple Silicon, so
arm64users should expect to build locally.
Verdict Anyone prepping for ML engineering loops at research labs or big-tech AI teams should bookmark this. If you already write custom CUDA kernels for fun, you’ll find the early problems remedial.
Frequently asked
- What is duoan/TorchCode?
- A notebook-based judge that auto-grades your from-scratch PyTorch implementations, because whiteboard interviews demand muscle memory, not paper reading.
- Is TorchCode open source?
- Yes — duoan/TorchCode is an open-source project tracked on heatdrop.
- What language is TorchCode written in?
- duoan/TorchCode is primarily written in Jupyter Notebook.
- How popular is TorchCode?
- duoan/TorchCode has 4.4k stars on GitHub and is currently cooling off.
- Where can I find TorchCode?
- duoan/TorchCode is on GitHub at https://github.com/duoan/TorchCode.