docker/genai-stack
Docker's all-in-one GenAI sandbox: five apps, one compose up
A batteries-included demo stack wiring LangChain, Neo4j, and Ollama into runnable RAG examples.
Not currently ranked — collecting fresh signals.
star history
What it does
This repo is Docker’s reference architecture for building retrieval-augmented generation (RAG) apps locally. docker compose up spins five containerized apps—support bot, Stack Overflow loader, PDF reader, HTTP API, and a Svelte front-end—backed by Neo4j as both vector store and knowledge graph. Ollama runs locally on Linux (containerized) or Mac/Windows (host-native); OpenAI, Claude, and Google models are one .env variable away.
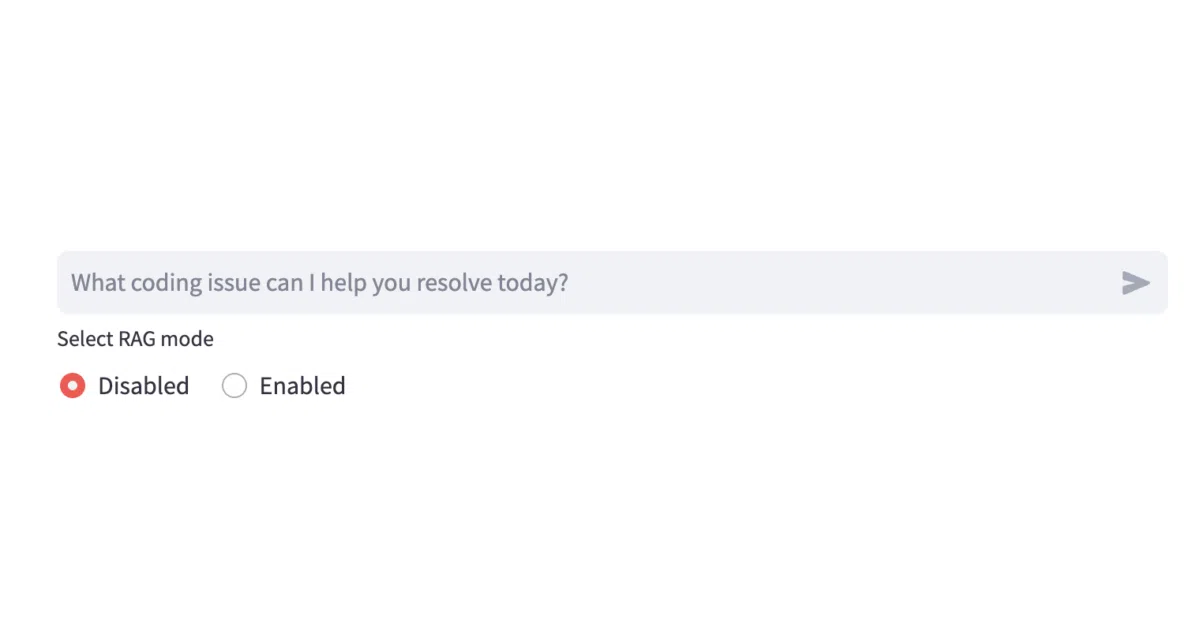
The interesting bit The support bot explicitly toggles between “RAG Disabled” (pure LLM hallucination mode) and “RAG Enabled” (vector search + knowledge graph context), making the value of grounding painfully obvious. It also auto-generates support tickets by mimicking the style of highly-rated Stack Overflow questions—a neat trick that actually uses the graph structure, not just vector similarity.
Key highlights
- Five demo apps with separate ports (8501–8505), from Streamlit prototypes to a standalone SSE API
- Neo4j serves dual duty: vector embeddings and knowledge graph relationships
- Ollama containerized for Linux (including GPU profile), host-native for Mac/Windows
docker compose watchfor live reload during development- PDF ingestion chunks text, embeds it, and answers via vector similarity search
Caveats
- Docker Desktop 4.24.x has a known performance regression with Python containers; upgrade first
- Mac/Windows users must run
ollama serveseparately beforedocker compose up - The README warns that failed health checks may require a full
docker compose downto recover
Verdict Good for developers who want to see RAG patterns wired together in working code before building their own. Skip it if you already have opinions about your vector database and just need another chatbot wrapper.
Frequently asked
- What is docker/genai-stack?
- A batteries-included demo stack wiring LangChain, Neo4j, and Ollama into runnable RAG examples.
- Is genai-stack open source?
- Yes — docker/genai-stack is open source, released under the CC0-1.0 license.
- What language is genai-stack written in?
- docker/genai-stack is primarily written in Python.
- How popular is genai-stack?
- docker/genai-stack has 5.3k stars on GitHub.
- Where can I find genai-stack?
- docker/genai-stack is on GitHub at https://github.com/docker/genai-stack.