deeplethe/forkd
Fork 100 Firecracker VMs in 101 ms, branch live ones too
forkd exists because cold-booting a sandbox for every AI agent thought is too slow; it lets a warm Firecracker parent snapshot its RAM so children inherit everything copy-on-write, mid-thought if needed.
Not currently ranked — collecting fresh signals.
star history
What it does
forkd is a sandbox runtime built on a vendored Firecracker that turns a warmed microVM snapshot into a copy-on-write template. The parent boots once, loads your runtime—Python imports, a JIT-warmed JVM, an already-loaded model—and pauses to disk. Each child Firecracker process mmaps that parent image with MAP_PRIVATE, letting the kernel handle page-level CoW. The README reports 101 ms to spawn 100 such sandboxes, with a memory delta of roughly 0.12 MiB per child.
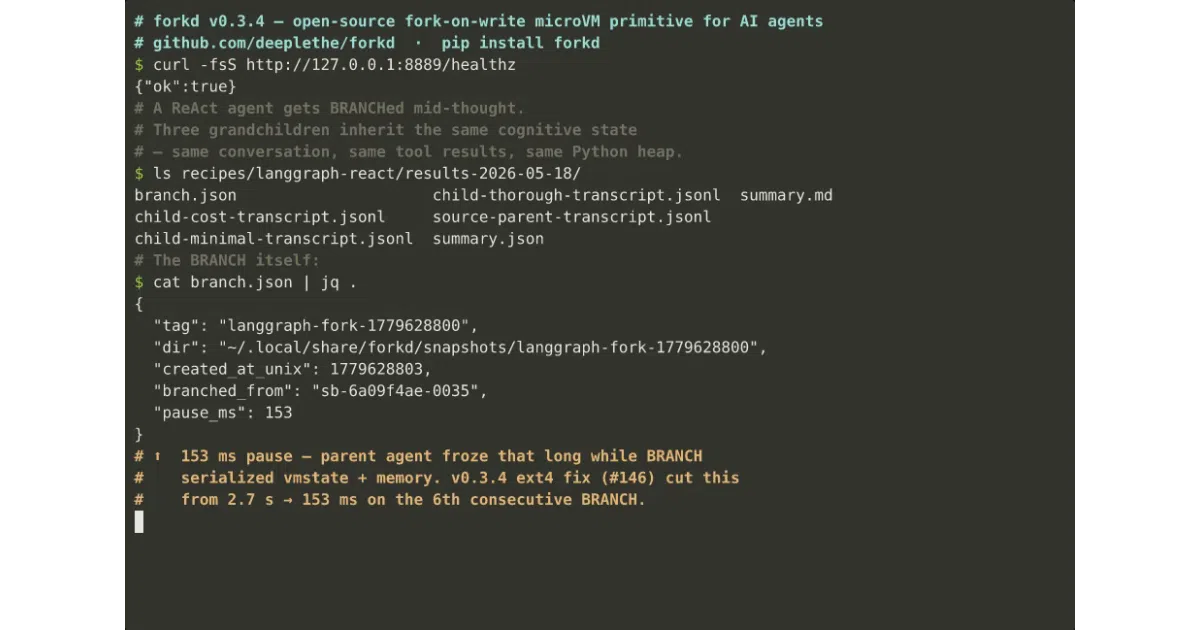
The interesting bit
The BRANCH primitive lets you pause a running sandbox, snapshot its in-flight state, and resume in about 150 ms—or 56 ms p50 in v0.4 live mode—so an agent can fork mid-thought rather than only from a static warm-up image. The v0.4 live path shrinks the source-pause window by moving memory copy after resume, making the operation nearly disk-independent.
Key highlights
- Speed claims from the README: 100 sandboxes in 101 ms versus 759 ms for raw Firecracker cold boot, 1.06 s for CubeSandbox, and over 100 s for Docker or gVisor on the same Ubuntu 24.04 host.
- Inheritance, not duplication: Children share the parent’s resident memory until they write, so warmed runtimes, prefetched caches, and even 50 MiB binary blobs travel across sandboxes without being rebuilt.
- Real Linux per child: Each sandbox gets multi-vCPU, full TCP networking, and its own network namespace and cgroup v2 memory limit—no single-vCPU serial-I/O trade-offs.
- Operational surface: A daemon owns state, exposes a REST API, serves Prometheus metrics, and keeps an append-only JSON audit log.
- Open source: Apache 2.0, no vendor SDK required.
Caveats
- It requires Linux ≥ 5.7,
vm.unprivileged_userfaultfd=1(orCAP_SYS_PTRACE), and a specific vendored Firecracker fork;forkd doctorprobes the host, but this is not a drop-in for generic Kubernetes nodes. - The v0.4 live BRANCH and CLI spawn paths do not yet compose end-to-end (issue #209), so some assembly is required depending on which API surface you use.
- The comparison benchmarks are run on a specific 20 vCPU / 30 GiB / Linux 6.14 box; your mileage will vary on different shapes or storage.
Verdict
If you are building AI agent infrastructure that needs to fan out into hundreds of short-lived, fully isolated sandboxes without paying the cold-boot tax on every import, forkd is worth a hard look. If you just need a few long-lived containers or function-level snapshots, it is probably overkill.
Frequently asked
- What is deeplethe/forkd?
- forkd exists because cold-booting a sandbox for every AI agent thought is too slow; it lets a warm Firecracker parent snapshot its RAM so children inherit everything copy-on-write, mid-thought if needed.
- Is forkd open source?
- Yes — deeplethe/forkd is open source, released under the Apache-2.0 license.
- What language is forkd written in?
- deeplethe/forkd is primarily written in Rust.
- How popular is forkd?
- deeplethe/forkd has 2.7k stars on GitHub.
- Where can I find forkd?
- deeplethe/forkd is on GitHub at https://github.com/deeplethe/forkd.