dbolya/tide
Your object detector scores 90% AP. TIDE asks: which 10% is lying?
A diagnostic drop-in for COCO evaluation that breaks down errors by type instead of flattening them into a single number.
Not currently ranked — collecting fresh signals.
star history
What it does
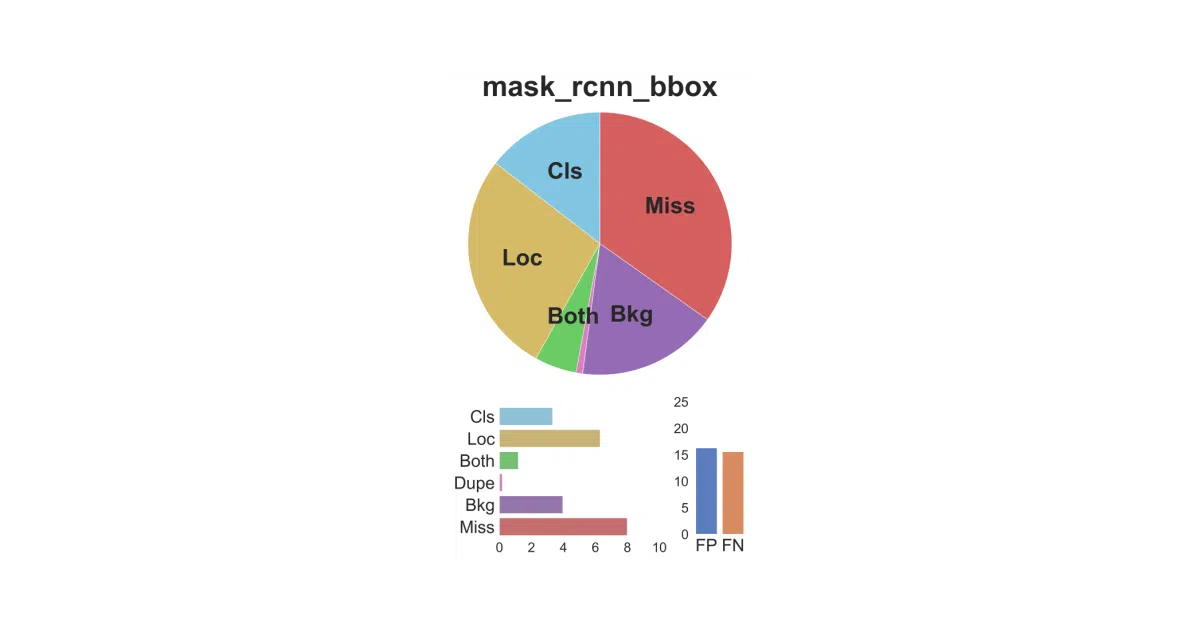
TIDE replaces the standard COCO evaluation toolkit with a forensic accountant. Instead of one AP score, it reports how much each error type—classification, localization, duplicates, background confusion, missed detections—contributes to the gap between your model and perfection. It works for bounding boxes and instance segmentation, and supports COCO, LVIS, Pascal, and Cityscapes out of the box.
The interesting bit
The cleverness is in the accounting: TIDE quantifies each error type as a “delta AP” (dAP), showing exactly how many percentage points each failure mode costs you. A model with 61.8 bbox AP might be losing 7.5 to missed detections, 6.6 to localization slop, and 3.4 to classification confusion—information the standard toolkit simply discards.
Key highlights
- Drop-in replacement: swap
tide.evaluate()for your COCO eval call, keep your results file - Two-line summary:
tide.summarize()for tables,tide.plot()for a summary figure - Published at ECCV 2020 (Spotlight), with a 4-minute explainer video
- Installable via
pip install tidecv(Python 3.6+) - Jupyter notebook example included for COCO instance segmentation
Caveats
- Documentation for writing custom dataset drivers is “coming soon” per the README
- Author notes email responses may be slow; GitHub issues are the reliable channel
Verdict
Worth it if you’re iterating on detector architecture and need to know whether to chase better NMS, stronger classification, or tighter regression. Skip it if you’re happy treating your model as a black box that either passes or fails a threshold.
Frequently asked
- What is dbolya/tide?
- A diagnostic drop-in for COCO evaluation that breaks down errors by type instead of flattening them into a single number.
- Is tide open source?
- Yes — dbolya/tide is open source, released under the MIT license.
- What language is tide written in?
- dbolya/tide is primarily written in Python.
- How popular is tide?
- dbolya/tide has 741 stars on GitHub.
- Where can I find tide?
- dbolya/tide is on GitHub at https://github.com/dbolya/tide.