datalab-to/surya
One 650M VLM reads your docs, tables, and fine print
Surya exists because most OCR tools treat text, layout, and tables as separate problems; it handles all three with a single 650M-parameter vision-language model.
Velocity · 7d
+5.1
★ / day
Trend
→steady
star history
What it does
Surya is a 650M-parameter document intelligence model that performs OCR, layout analysis, reading-order detection, and table recognition through a single vision-language backend. It ingests images or PDFs and returns structured blocks—each tagged with a layout label like SectionHeader or Table, a reading-order index, an HTML snippet, and a bounding polygon. A separate inference manager handles the heavy lifting, auto-spawning a local vllm or llama.cpp server so you do not have to wire up the VLM boilerplate yourself.
The interesting bit
The project consolidates what used to be separate pipelines into one VLM call per page, yet it keeps the output strictly structured rather than free-form text. That is a tricky balance: most VLMs excel at prose but fumble at precise spatial coordinates and canonical labels, whereas Surya emits both. The README also notes the model is named for a Hindu sun god with universal vision, which feels apt for a tool whose whole job is to see everything on the page at once.
Key highlights
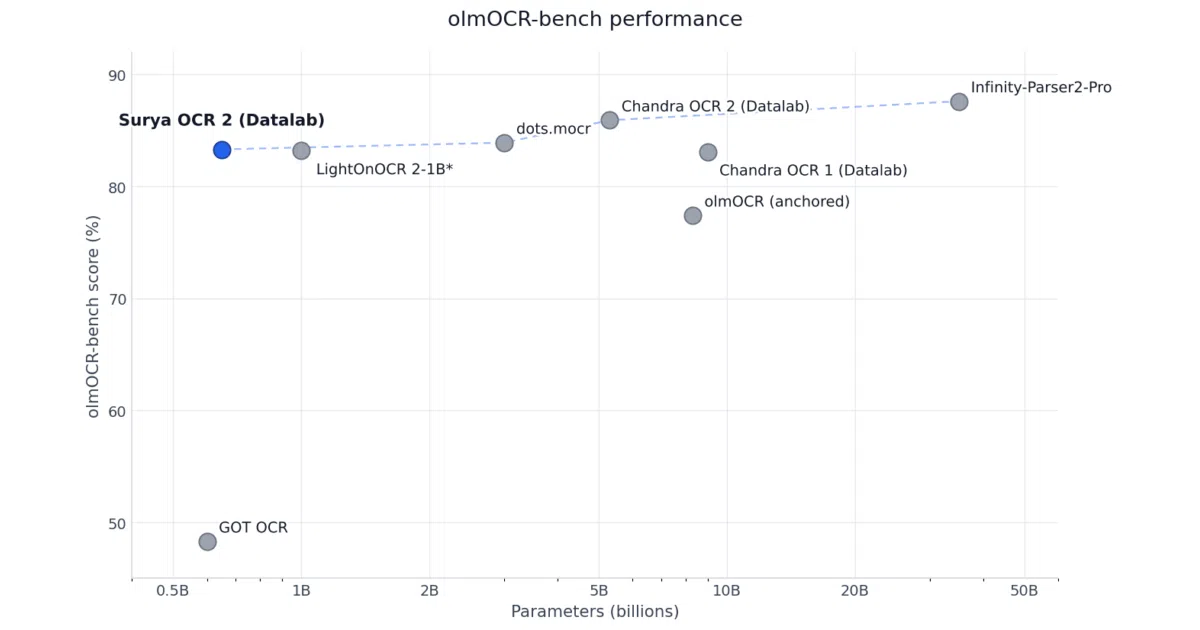
- Scores 83.3% on the olmOCR-bench benchmark, which the authors claim is the best among models under 3B parameters.
- Supports 91 languages, scoring 87.2% on an internal multilingual benchmark.
- Outputs blocks as HTML where appropriate—math wrapped in
<math>tags, tables in<table>structures—so downstream tools get semantic markup, not just raw strings. - Runs locally via
vllmon NVIDIA hardware orllama.cppon CPU and Apple Silicon; theSuryaInferenceManagerabstracts the server lifecycle. - Achieves a throughput of 5 pages per second on an RTX 5090, though the README notes this depends heavily on backend tuning and DPI settings.
Caveats
- Model weights use a modified OpenRAIL-M license that is free only for research, personal use, and startups under $5M in funding or revenue; broader commercial use requires a separate paid license from Datalab.
- By default, every CLI command spawns its own VLM server and tears it down on exit, so repeated runs pay the startup and model-load cost each time unless you explicitly enable keep-alive behavior.
- Version 2 introduced breaking schema changes from v1—
text_linesbecameblocks, layout output droppedtop_k, and table cells lostis_header/colspan/rowspan—so existing integrations will need migration work.
Verdict
Ideal for developers building document pipelines who need multilingual OCR plus structural understanding in a single, relatively small model. Skip it if you require fully unrestricted commercial model weights or if you are unwilling to manage a local VLM server backend.
Frequently asked
- What is datalab-to/surya?
- Surya exists because most OCR tools treat text, layout, and tables as separate problems; it handles all three with a single 650M-parameter vision-language model.
- Is surya open source?
- Yes — datalab-to/surya is open source, released under the Apache-2.0 license.
- What language is surya written in?
- datalab-to/surya is primarily written in Python.
- How popular is surya?
- datalab-to/surya has 21.1k stars on GitHub and is currently holding steady.
- Where can I find surya?
- datalab-to/surya is on GitHub at https://github.com/datalab-to/surya.