darkrishabh/agent-skills-eval
Receipts for your AI skill claims
A test runner that proves whether your Agent Skills actually make models better, or just make you feel better.
Not currently ranked — collecting fresh signals.
star history
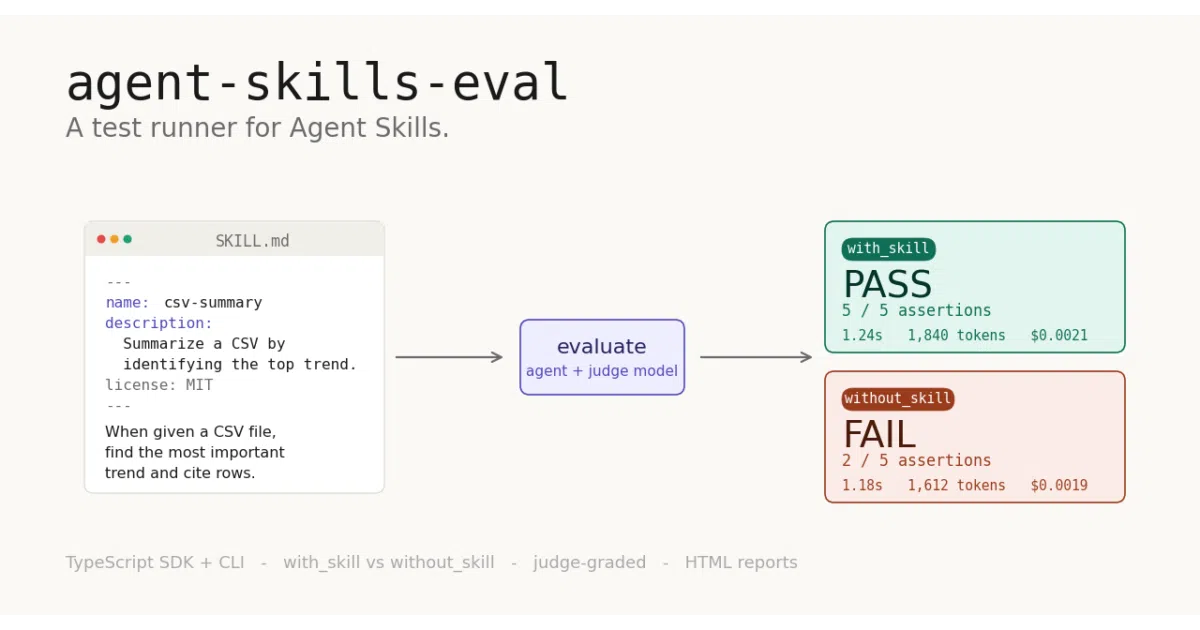
What it does
agent-skills-eval is a CLI and TypeScript SDK that runs your SKILL.md files through controlled experiments. For every eval, it prompts a target model twice — once with your skill loaded, once without — then has a judge model grade both outputs against the same assertions. The result is a side-by-side pass/fail report with actual evidence, not vibes.
The interesting bit
The baseline comparison is the whole point. Most skill frameworks let you ship a SKILL.md and assume improvement; this tool makes the absence of the skill a first-class test condition. If your skill doesn’t move the needle, the HTML report shows it plainly — which is arguably more valuable than confirmation bias.
Key highlights
- Runs
with_skillvswithout_skillfor every eval, producing comparable pass/fail grades - Judge model uses cited assertions against
expected_output; auto-promotes expected output to assertion if you skip explicit ones - OpenAI-compatible API by default; custom providers need only one
complete()method - Static HTML reports from JSON/JSONL artifacts — no infrastructure, diffable across runs
- Full
agentskills.iospec compliance:SKILL.mdvalidation,evals/evals.jsonschema, officialiteration-Nlayout - YAML config, programmatic SDK, and one-liner CLI all supported
Caveats
- Requires you to already have evals written in the
agentskills.ioformat; not a general LLM benchmark suite - Judge model quality directly determines grading quality — garbage in, garbage out
--baselinedoubles your API costs per eval; the README notes this flag is optional but the value proposition basically requires it
Verdict
Worth it if you’re building or curating Agent Skills and need empirical proof they work. Skip if you’re looking for generic LLM evaluation or don’t want to commit to the agentskills.io folder-and-JSON structure.
Frequently asked
- What is darkrishabh/agent-skills-eval?
- A test runner that proves whether your Agent Skills actually make models better, or just make you feel better.
- Is agent-skills-eval open source?
- Yes — darkrishabh/agent-skills-eval is open source, released under the MIT license.
- What language is agent-skills-eval written in?
- darkrishabh/agent-skills-eval is primarily written in TypeScript.
- How popular is agent-skills-eval?
- darkrishabh/agent-skills-eval has 631 stars on GitHub.
- Where can I find agent-skills-eval?
- darkrishabh/agent-skills-eval is on GitHub at https://github.com/darkrishabh/agent-skills-eval.