chrischoy/3D-R2N2
Turning eBay photos into 3D voxels with recurrent memory
A 2016 ECCV paper that unifies single and multi-view 3D reconstruction by stuffing 2D image features into 3D convolutional LSTMs.
Not currently ranked — collecting fresh signals.
star history
What it does
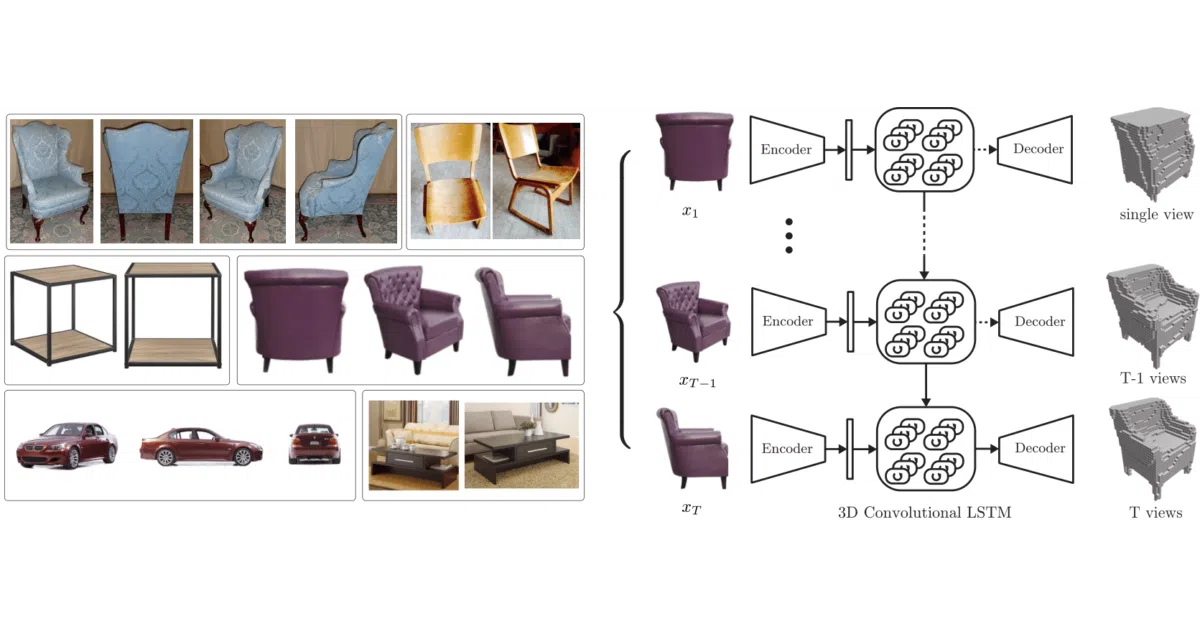
Feed the network one photo—or several, in any order—and it spits out a voxelized 3D model of the object. It was trained on rendered ShapeNet images and corresponding 32³ voxel grids, and the demo shows it reconstructing a chair from three arbitrary views.
The interesting bit
The trick is a 3D-Convolutional LSTM that sits inside the reconstruction volume itself. It selectively updates voxels where the new view reveals surface, and leaves occluded regions untouched—so shuffled inputs don’t scramble the output. The authors also note that dense voxel grids are memory-hungry, and have since moved to sparse tensors (see their MinkowskiEngine follow-up).
Key highlights
- Unified single-view and multi-view reconstruction in one architecture
- Order-invariant: images can arrive in any sequence
- Two network variants: shallow net and deep residual GRU net
- Pre-trained weights and full ShapeNet pipeline provided
- Interactive result viewer hosted at project page
Caveats
- Built on Theano and Python 3.6; the README warns of slow first-time compilation
- Requires separate cuDNN setup and manual environment variable wrangling
- Demo visualization depends on MeshLab or another external mesh viewer
Verdict
Worth a look for computer-vision researchers tracing the lineage of 3D reconstruction, or anyone curious how LSTM memory was once wedged into volumetric space. Skip it if you need modern sparse reconstruction or a PyTorch-native toolchain.
Frequently asked
- What is chrischoy/3D-R2N2?
- A 2016 ECCV paper that unifies single and multi-view 3D reconstruction by stuffing 2D image features into 3D convolutional LSTMs.
- Is 3D-R2N2 open source?
- Yes — chrischoy/3D-R2N2 is open source, released under the MIT license.
- What language is 3D-R2N2 written in?
- chrischoy/3D-R2N2 is primarily written in Python.
- How popular is 3D-R2N2?
- chrischoy/3D-R2N2 has 1.4k stars on GitHub.
- Where can I find 3D-R2N2?
- chrischoy/3D-R2N2 is on GitHub at https://github.com/chrischoy/3D-R2N2.