caiyuanhao1998/Open-OmniVCus
Drop a subject into generated video using depth, mask, or motion
This project automates the construction of multimodal video training pairs and provides feedforward diffusion transformers to insert a specific subject into a scene guided by depth, mask, or motion conditions.
Not currently ranked — collecting fresh signals.
star history
What it does
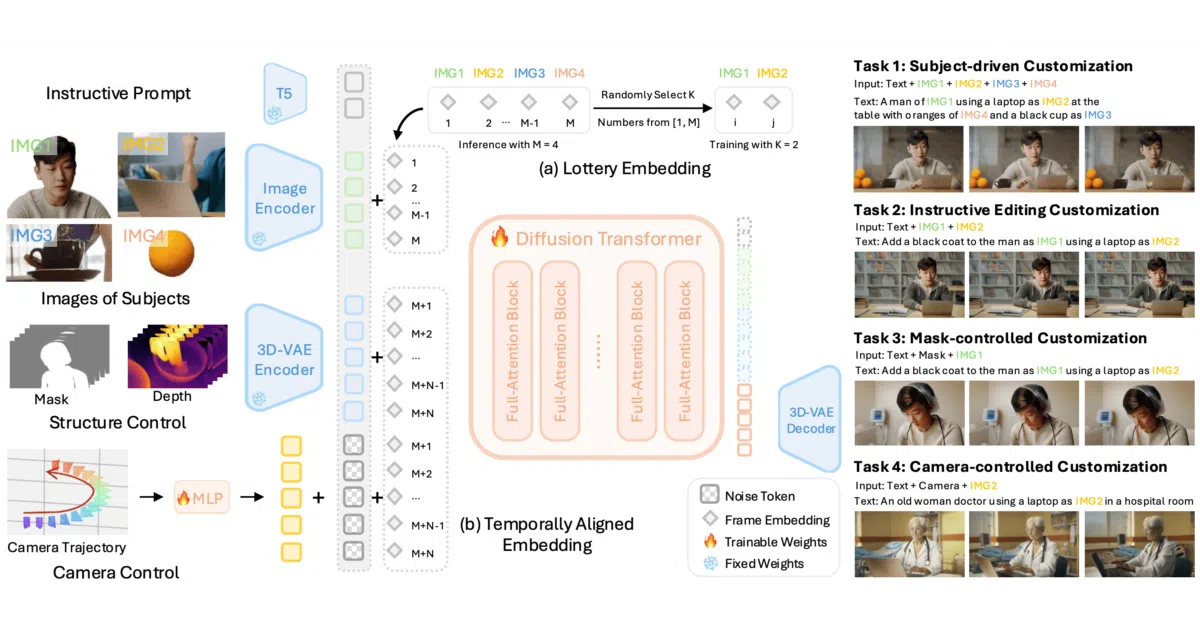
OmniVCus is a re-implementation of a NeurIPS 2025 paper that generates videos where a specific subject—provided as a reference image—appears in a new scene. It accepts multimodal control signals such as depth video, segmentation masks, or motion flow to guide generation. The repository includes both a data construction toolkit, VideoCus-Factory, that turns raw videos into annotated training pairs, and fine-tuned diffusion transformers in DiffSynth-Studio built on Wan2.1, Wan2.2, and VACE backbones.
The interesting bit
The feedforward design means you do not fine-tune the model for every new subject at inference time; you simply hand it a reference image and a control signal. The project also automates the critical work of creating training data—segmenting subjects, augmenting them, and extracting depth, mask, and optical flow—from raw video clips.
Key highlights
- Feedforward inference: one reference image plus a control condition, no per-subject optimization.
- Multimodal control via depth video, mask video, motion flow, and subject references.
- Complete data construction pipeline (
VideoCus-Factory) for generating training pairs from raw video. - Fine-tuned model variants for
Wan2.1(1.3B and 14B),Wan2.2(14B), andVACE, with tensor-parallel training and inference scripts. - Pre-trained weights and constructed datasets published on HuggingFace.
Caveats
- The author notes this is a re-implementation built from public datasets and codes, and that the repository is still being completed.
- Setup and environment details are scattered across subfolders rather than centralized in the top-level README.
Verdict
Worth a look if you are researching subject-driven video generation or need a ready-made data factory for video diffusion training. Skip it if you want a polished, end-to-end application with centralized documentation.
Frequently asked
- What is caiyuanhao1998/Open-OmniVCus?
- This project automates the construction of multimodal video training pairs and provides feedforward diffusion transformers to insert a specific subject into a scene guided by depth, mask, or motion conditions.
- Is Open-OmniVCus open source?
- Yes — caiyuanhao1998/Open-OmniVCus is an open-source project tracked on heatdrop.
- What language is Open-OmniVCus written in?
- caiyuanhao1998/Open-OmniVCus is primarily written in Python.
- How popular is Open-OmniVCus?
- caiyuanhao1998/Open-OmniVCus has 500 stars on GitHub.
- Where can I find Open-OmniVCus?
- caiyuanhao1998/Open-OmniVCus is on GitHub at https://github.com/caiyuanhao1998/Open-OmniVCus.