bytedance/LatentSync
Stable Diffusion learns to lip-sync, no motion middlemen required
It generates lip-synced faces by feeding Whisper audio embeddings straight into a latent diffusion U-Net, skipping the usual motion-representation detour.
Not currently ranked — collecting fresh signals.
star history
What it does
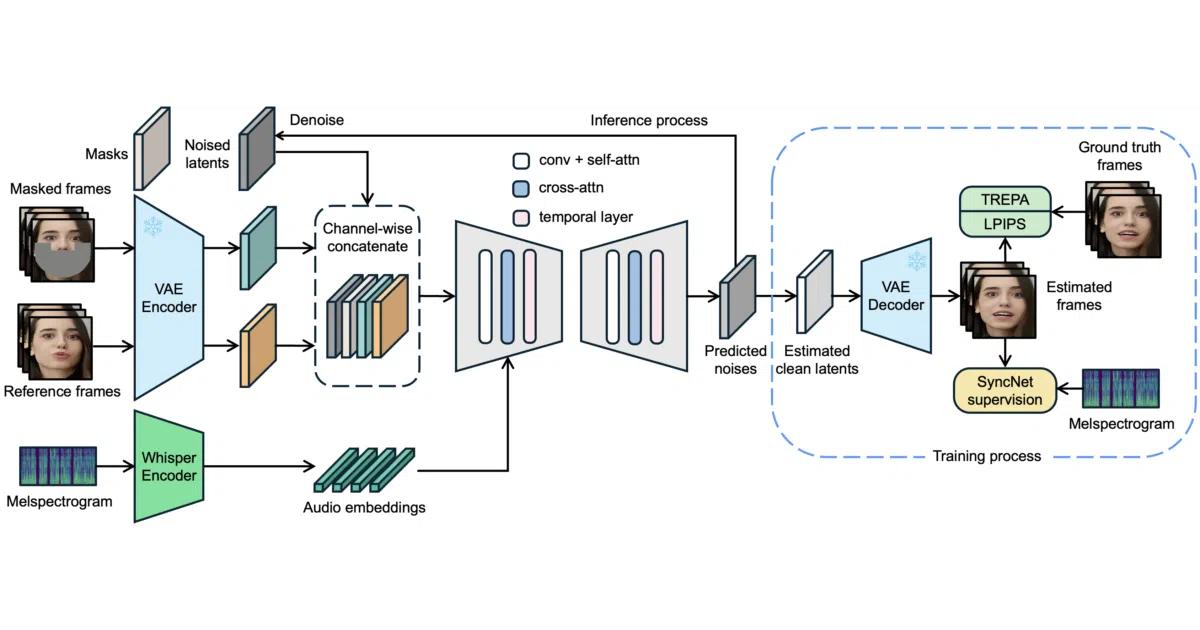
LatentSync is an end-to-end lip-sync method that maps audio to facial motion using a latent diffusion model built atop Stable Diffusion. It ingests video frames and a Whisper-derived audio embedding, then uses cross-attention inside a U-Net to predict denoised latents that match the speaker’s mouth to the soundtrack. The result is a generated video clip where the lips follow the audio without any intermediate motion representation or separate puppeteering stage.
The interesting bit
Previous diffusion-based lip-sync approaches worked in pixel space or required two-stage generation; LatentSync stays entirely in the latent domain, channel-wise concatenating reference and masked frames with noised latents as U-Net input. During training, a one-step estimate decodes predicted noise back to clean frames in pixel space so that TREPA, LPIPS, and SyncNet losses can supervise the model directly—essentially using the diffusion process as a video editor rather than a painter.
Key highlights
- Runs inference at 8 GB VRAM for the 1.5 model or 18 GB for the sharper 512×512 1.6 release.
- Ships the full stack: inference checkpoints, data-processing pipeline, training scripts, and a pretrained
SyncNetthat scores 94% accuracy on VoxCeleb2 and HDTF. - The data pipeline is opinionated: it resamples, scene-detects, face-aligns via
InsightFace, and filters by sync confidence andhyperIQAscore before a frame ever sees the U-Net. - Training configs span 20 GB to 55 GB VRAM depending on stage and resolution, with an efficient stage-2 config aimed at consumer cards like the RTX 3090.
- Built on
AnimateDiffand borrows fromMuseTalk,StyleSync, andWav2Lip—this is research code assembled from battle-tested parts.
Caveats
- The 1.6 release demands 18 GB VRAM for 512×512 inference, while the earlier 1.5 model runs on 8 GB but at lower resolution.
- Higher
guidance_scaleimproves sync accuracy at the cost of distortion or jitter, so tuning the trade-off is mandatory. - The authors note that evaluation requires preprocessing test data through their exact pipeline (affine transforms and audio-visual offset fixes), or the pretrained
SyncNetwill not behave as expected.
Verdict
Worth exploring if you are training or inferring lip-sync models at scale and can budget 8–18 GB of VRAM; if you need a lightweight drop-in filter for a laptop, this diffusion-based approach is likely overkill.
Frequently asked
- What is bytedance/LatentSync?
- It generates lip-synced faces by feeding Whisper audio embeddings straight into a latent diffusion U-Net, skipping the usual motion-representation detour.
- Is LatentSync open source?
- Yes — bytedance/LatentSync is open source, released under the Apache-2.0 license.
- What language is LatentSync written in?
- bytedance/LatentSync is primarily written in Python.
- How popular is LatentSync?
- bytedance/LatentSync has 5.9k stars on GitHub.
- Where can I find LatentSync?
- bytedance/LatentSync is on GitHub at https://github.com/bytedance/LatentSync.