bradyz/cross_view_transformers
Stitching multi-view cameras into real-time semantic maps
This repo fuses multi-view camera images into bird's-eye semantic maps at 45 FPS by learning which image patches matter via cross-view attention.
Not currently ranked — collecting fresh signals.
star history
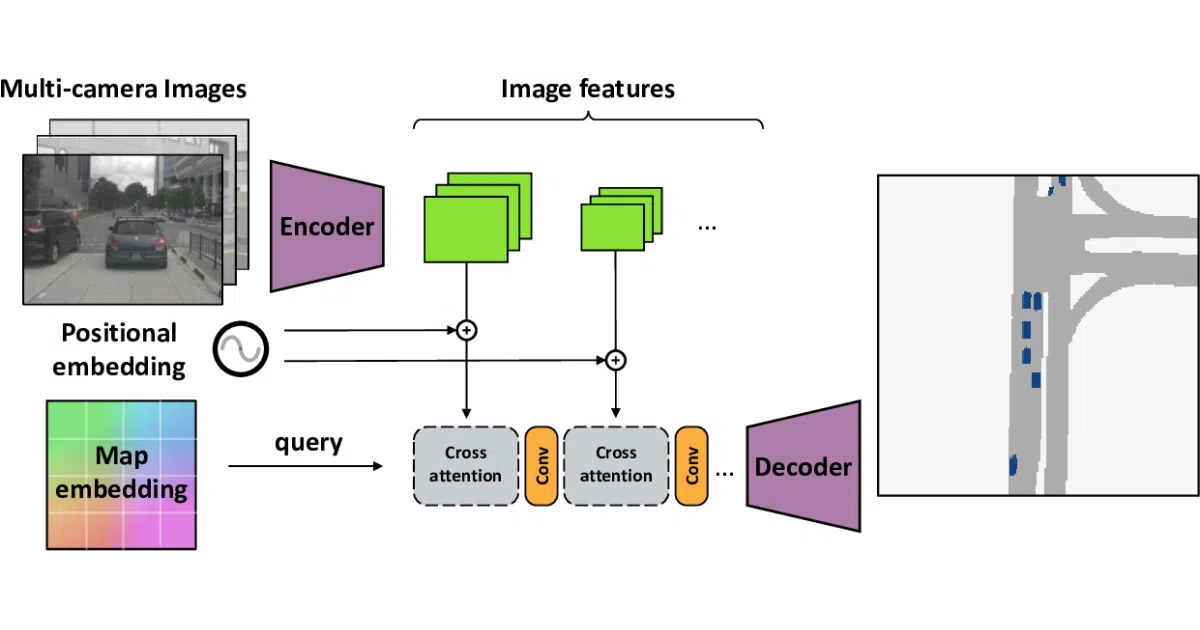
What it does Cross-view Transformers is the research code behind a CVPR 2022 Oral paper that generates top-down semantic maps from multiple vehicle cameras in real time. The model produces bird’s-eye-view segmentation at 45 FPS and can accumulate predictions over time into a consistent map when vehicle pose is available. The codebase includes training infrastructure built on PyTorch Lightning, Hydra, and WandB, along with generated labels for the nuScenes dataset.
The interesting bit The network uses cross-view attention: each map location directly attends to relevant patches across the input images. The README includes attention visualizations that show exactly which camera pixels are being queried for each point on the road.
Key highlights
- Real-time map-view segmentation at 45 FPS from multi-view images.
- Cross-view attention links each map location directly to relevant patches across the input images.
- Temporal fusion stitches predictions into a coherent map using vehicle pose over time.
- Provides generated map-view labels for nuScenes (Argoverse 1.1 labels are listed as “coming soon™”).
- MIT-licensed PyTorch implementation with configurable Hydra experiments.
Caveats
- Argoverse 1.1 labels are marked “coming soon™,” so only nuScenes is fully supported out of the box.
- Pretrained checkpoints are not mentioned; expect to train from scratch using the provided configs (the README cites ~8 hours on 4 GPUs).
- Getting started requires downloading ~60 GB of nuScenes keyframes plus separately extracted labels.
Verdict A useful reference if you are researching bird’s-eye-view perception from multi-view camera feeds or need an attention-based baseline for driving scene understanding. Skip it if you need a drop-in pretrained model or a lightweight dataset to experiment with casually.
Frequently asked
- What is bradyz/cross_view_transformers?
- This repo fuses multi-view camera images into bird's-eye semantic maps at 45 FPS by learning which image patches matter via cross-view attention.
- Is cross_view_transformers open source?
- Yes — bradyz/cross_view_transformers is open source, released under the MIT license.
- What language is cross_view_transformers written in?
- bradyz/cross_view_transformers is primarily written in Python.
- How popular is cross_view_transformers?
- bradyz/cross_view_transformers has 574 stars on GitHub.
- Where can I find cross_view_transformers?
- bradyz/cross_view_transformers is on GitHub at https://github.com/bradyz/cross_view_transformers.