beader/tianchi_nl2sql
Third place in a Chinese NL2SQL contest, explained in notebooks
A readable, medal-winning approach to turning natural language questions into SQL using BERT and a clever two-model decomposition.
Not currently ranked — collecting fresh signals.
star history
What it does
This repo documents the 3rd-place solution to the first Chinese NL2SQL challenge, where the task is to convert a natural language question plus a table schema into a structured SQL query. The code is organized as Jupyter notebooks with utility modules, intended for learning rather than exact reproduction of the competition score.
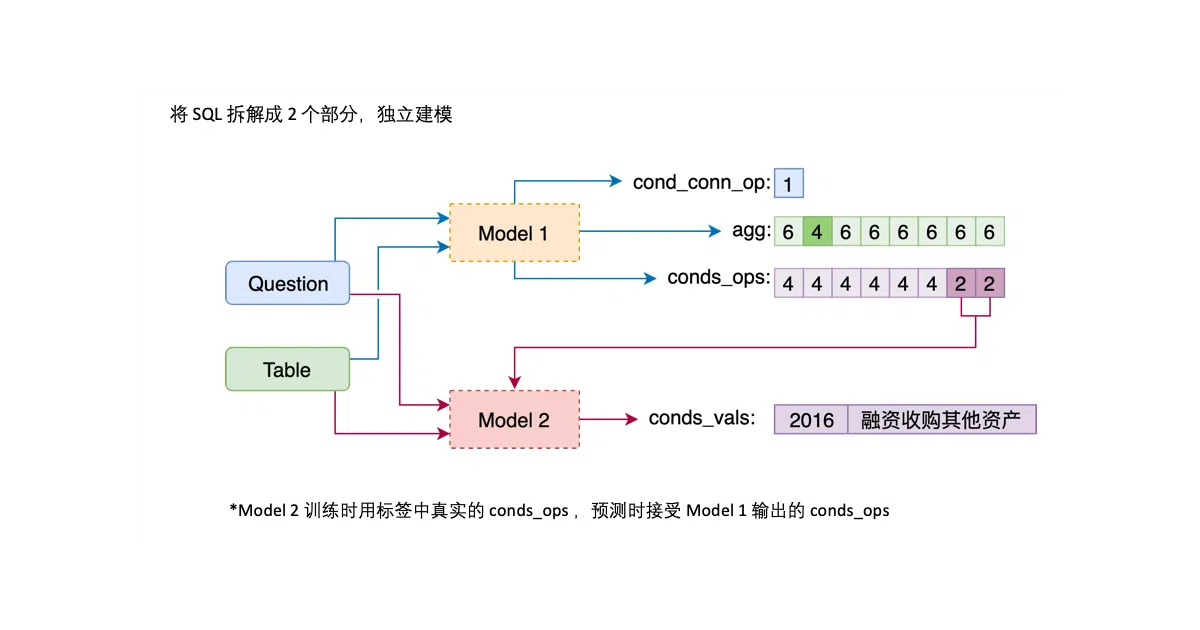
The interesting bit
The team splits the problem into two models: one predicts which columns to select and which conditions to apply (the “where” logic), and the second figures out the actual comparison values by treating candidate combinations as binary classification problems. They also merge SELECT and aggregation into a single prediction by adding a NO_OP class for unselected columns, which keeps the architecture cleaner.
Key highlights
- Built on
keras-bertwith the Chinese whole-word-masking BERT variant (Chinese-BERT-wwm) - Uses RAdam optimizer from Su Jianlin’s open-source implementation
- Model 1 injects
TEXT/REALtype tokens before each column header to hint schema types to BERT - Model 2 enumerates condition candidates and scores them independently, then merges
- Includes a Docker image and
requirements.txtfor the exact TensorFlow nightly + Python 3.6 environment used during the competition
Caveats
- The notebooks are cleaned-up for educational purposes and “will not fully reproduce the online results”
- Requires a specific nightly TensorFlow GPU build; the README suggests Docker to avoid dependency pain
Verdict
Worth studying if you’re building NL2SQL systems or want to see how competition solutions decompose messy structured prediction into tractable BERT fine-tuning steps. Skip if you need a production-ready library—this is reference code, not a packaged tool.
Frequently asked
- What is beader/tianchi_nl2sql?
- A readable, medal-winning approach to turning natural language questions into SQL using BERT and a clever two-model decomposition.
- Is tianchi_nl2sql open source?
- Yes — beader/tianchi_nl2sql is an open-source project tracked on heatdrop.
- What language is tianchi_nl2sql written in?
- beader/tianchi_nl2sql is primarily written in Jupyter Notebook.
- How popular is tianchi_nl2sql?
- beader/tianchi_nl2sql has 559 stars on GitHub.
- Where can I find tianchi_nl2sql?
- beader/tianchi_nl2sql is on GitHub at https://github.com/beader/tianchi_nl2sql.