awslabs/dgl-ke
AWS's graph embedding toolkit that outruns rivals on billion-edge KGs
A research-backed tool for training knowledge graph embeddings at scale, built on DGL and benchmarked against GraphVite and PyTorch-BigGraph.
Not currently ranked — collecting fresh signals.
star history
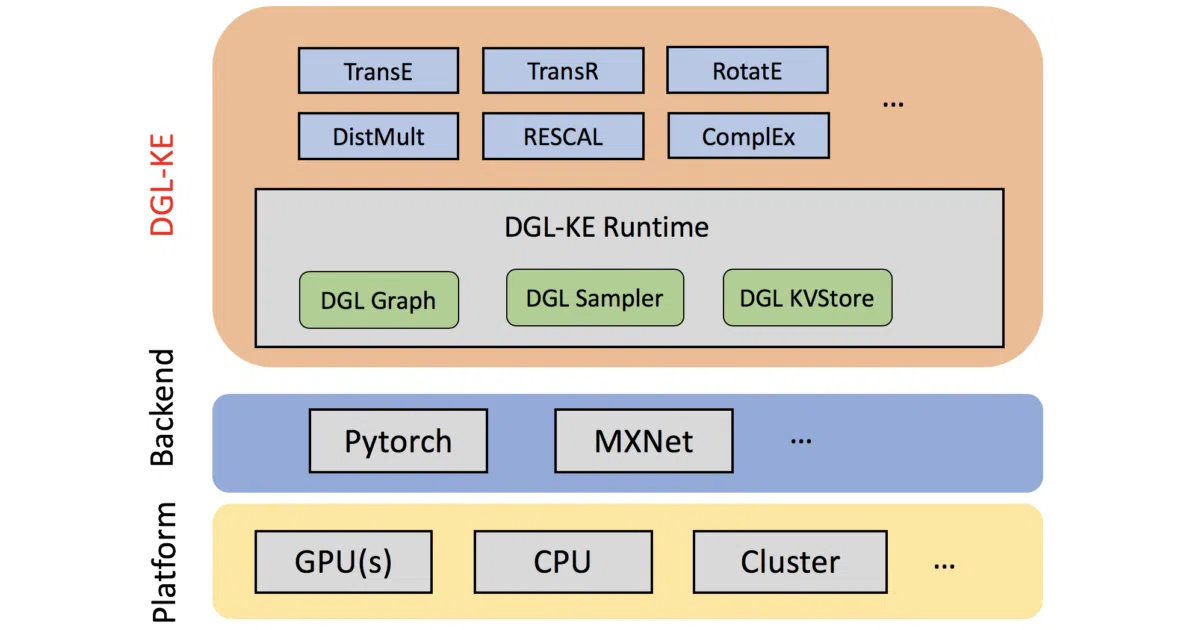
What it does DGL-KE trains, evaluates, and runs inference on knowledge graph embeddings — dense vector representations of entities and relations in graphs. It wraps six established models (TransE, TransR, RESCAL, DistMult, ComplEx, RotatE) in a command-line interface that works on single machines, GPUs, or distributed clusters.
The interesting bit The speed claims are specific and large: on a graph with 86M nodes and 338M edges, it finishes in 100 minutes on 8 GPUs or 30 minutes on a 4-machine CPU cluster, reportedly 2–5× faster than competing tools. The README pins these numbers to exact hardware and rival systems, which is rarer than you’d expect.
Key highlights
- Built on Deep Graph Library (DGL); PyTorch backend
- Distributed training via
dglke_dist_train, single-machine viadglke_train - Includes evaluation (
dglke_eval) and two inference modes: link prediction and embedding similarity - Ships with benchmark comparisons against GraphVite (FB15k) and PyTorch-BigGraph (Freebase)
- Published at SIGIR 2020 with a full optimization paper
Caveats
- The project appears in maintenance mode; the README now redirects TransE/DistMult/RotatE users to the newer GraphStorm project
- Installation still uses
sudo pip3, which may surprise modern Python developers
Verdict Worth a look if you’re embedding billion-scale knowledge graphs and need reproducible speed benchmarks. Skip it if you only need standard small-graph KGE — GraphStorm or plain PyTorch-BigGraph may be more actively maintained.
Frequently asked
- What is awslabs/dgl-ke?
- A research-backed tool for training knowledge graph embeddings at scale, built on DGL and benchmarked against GraphVite and PyTorch-BigGraph.
- Is dgl-ke open source?
- Yes — awslabs/dgl-ke is open source, released under the Apache-2.0 license.
- What language is dgl-ke written in?
- awslabs/dgl-ke is primarily written in Python.
- How popular is dgl-ke?
- awslabs/dgl-ke has 1.3k stars on GitHub.
- Where can I find dgl-ke?
- awslabs/dgl-ke is on GitHub at https://github.com/awslabs/dgl-ke.