apple/ml-4m
One foundation model, twenty-one vision dialects
It treats RGB, depth, captions, and bounding boxes as interchangeable tokens so a single transformer can map between any of them.
Not currently ranked — collecting fresh signals.
star history
What it does
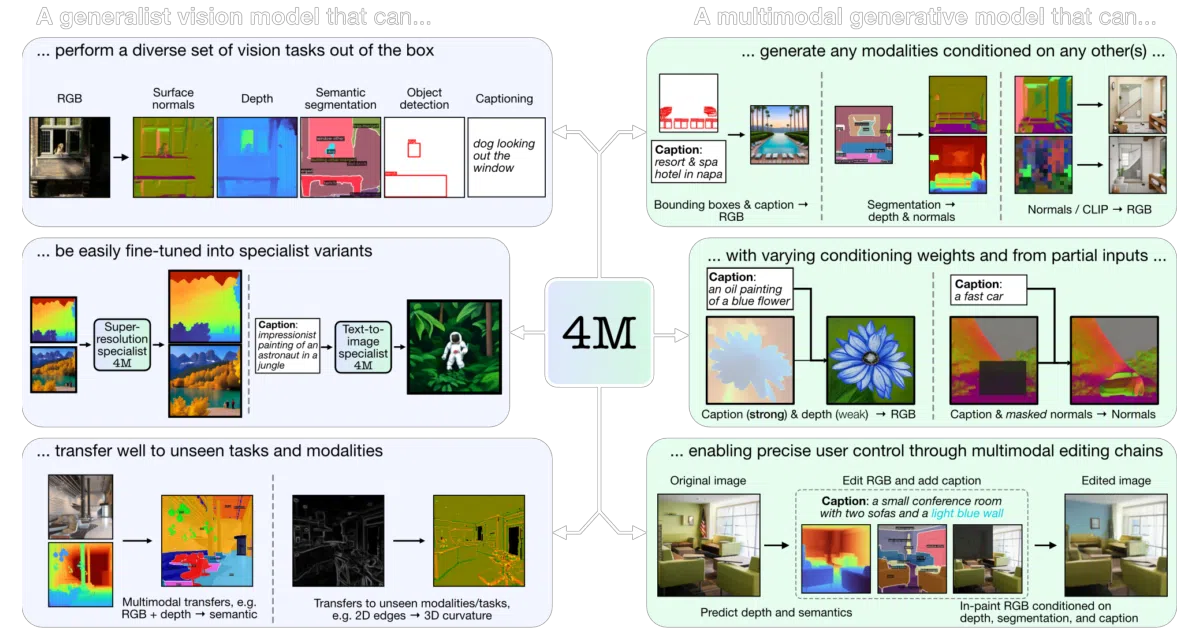
4M is a framework—and a family of released checkpoints—for training vision foundation models that map between many modalities instead of specializing in just one. It uses modality-specific tokenizers to map inputs like RGB images, depth maps, or captions into a shared discrete space, then trains a masked transformer to predict missing tokens. The released models can ingest one modality and generate others, or perform standard vision tasks such as captioning and bounding-box prediction.
The interesting bit
The architecture is designed as “any-to-any”: all modalities live in a single token vocabulary, so the model is not locked to fixed input-output pairs. This unified approach lets it transfer to unseen tasks by recomposing tokens it already understands.
Key highlights
- 4M-21 scales to 21 modalities, including RGB, depth, captions, and bounding boxes.
- Released checkpoints span 198M to 2.8B parameters, plus specialist models for text-to-image generation and super-resolution.
- Weights are published as safetensors on Hugging Face Hub.
- The release includes training code, custom tokenizers, and inference notebooks.
- Originated in a NeurIPS 2023 Spotlight paper and expanded in a 2024 follow-up by EPFL and Apple.
Verdict
Grab this if you are building multimodal vision pipelines and want a single backbone instead of a zoo of task-specific models. Skip it if you are simply looking for a polished, consumer-grade image generator.
Frequently asked
- What is apple/ml-4m?
- It treats RGB, depth, captions, and bounding boxes as interchangeable tokens so a single transformer can map between any of them.
- Is ml-4m open source?
- Yes — apple/ml-4m is open source, released under the Apache-2.0 license.
- What language is ml-4m written in?
- apple/ml-4m is primarily written in Python.
- How popular is ml-4m?
- apple/ml-4m has 1.8k stars on GitHub.
- Where can I find ml-4m?
- apple/ml-4m is on GitHub at https://github.com/apple/ml-4m.