anicolson/DeepXi
Speech enhancement by predicting a Greek letter nobody can pronounce
Deep Xi estimates a priori SNR with neural nets so you don't have to do the math yourself.
Not currently ranked — collecting fresh signals.
star history
What it does Deep Xi trains deep neural networks to estimate the a priori signal-to-noise ratio (SNR) from noisy speech magnitude spectra. That estimate then feeds into classic MMSE gain functions for speech enhancement, noise PSD estimation, or as a front-end for robust automatic speech recognition. It’s essentially a learned replacement for the decision-directed approach that speech people have been hand-tuning since the 1980s.
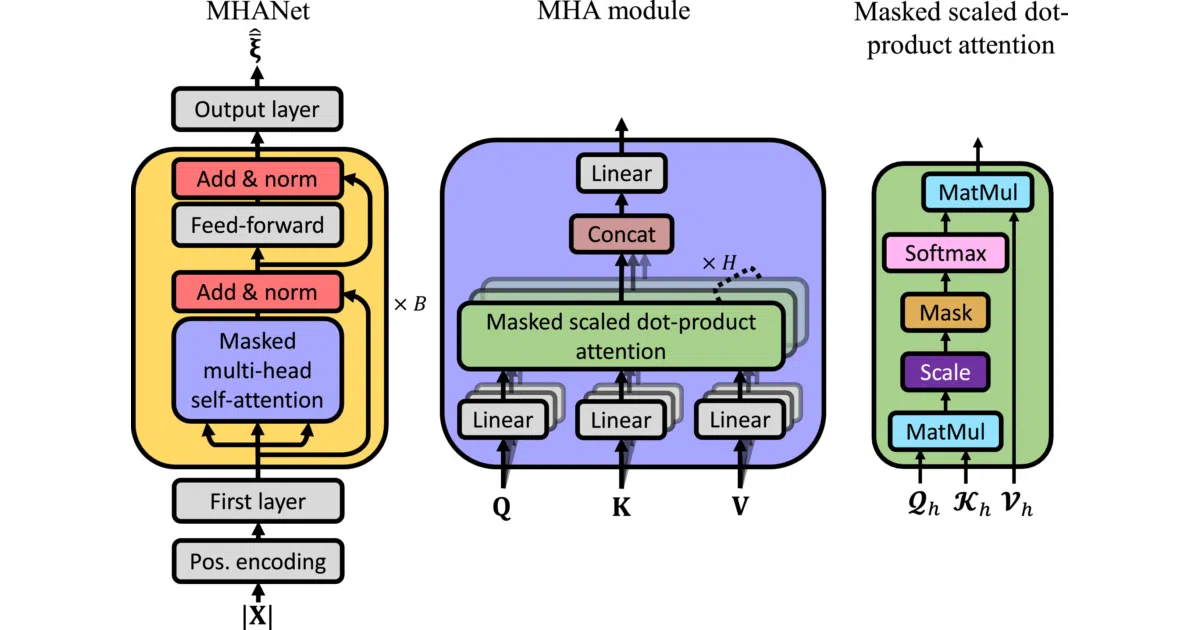
The interesting bit The target isn’t raw SNR—it’s a CDF-mapped version squeezed into [0,1] using statistics computed over the training set, then unmapped at inference. The README is admirably explicit that this improves SGD convergence. Several architectures are supported (MHANet, ResNet, ResLSTM, ResBiLSTM), with causal and non-causal variants, and pre-trained models are actually provided in the repo.
Key highlights
- TensorFlow 2/Keras implementation with sequence masking for variable-length batches
- Pre-trained MHANet and ResNet models available in the
model/directory - Trained on the dedicated Deep Xi dataset (linked, though you need to fetch it separately)
- Objective results on DEMAND Voice Bank and a custom test set; non-causal ResNet 1.1n scores highest on most metrics
- Also usable for ideal binary/ratio mask estimation and as an ASR front-end
Caveats
- The repo language is tagged MATLAB, but the implementation is TensorFlow 2/Keras—MATLAB appears limited to evaluation scripts (
eval_example.m,eval_stats.m) - Results in papers used TensorFlow 1; current numbers are TF2/Keras re-runs, and the README notes this explicitly
- The README is truncated mid-table for the Deep Xi Test Set results, so some numbers are cut off
Verdict Worth a look if you’re doing speech enhancement research and want a well-documented baseline with actual pre-trained weights. Skip if you need a polished, end-to-end product pipeline—the code is research-grade, and you’ll be doing your own data wrangling.
Frequently asked
- What is anicolson/DeepXi?
- Deep Xi estimates a priori SNR with neural nets so you don't have to do the math yourself.
- Is DeepXi open source?
- Yes — anicolson/DeepXi is open source, released under the MPL-2.0 license.
- What language is DeepXi written in?
- anicolson/DeepXi is primarily written in MATLAB.
- How popular is DeepXi?
- anicolson/DeepXi has 523 stars on GitHub.
- Where can I find DeepXi?
- anicolson/DeepXi is on GitHub at https://github.com/anicolson/DeepXi.